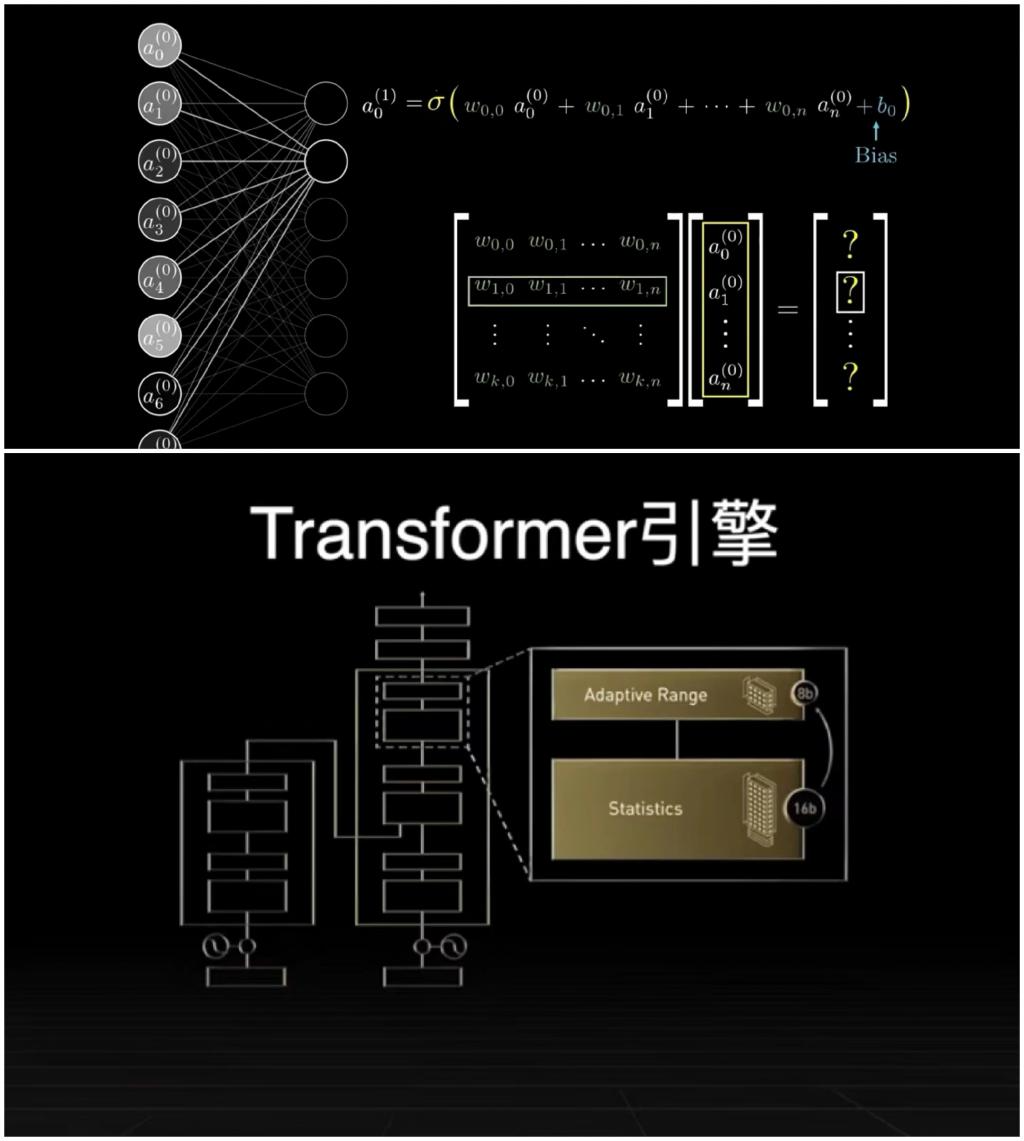
机器学习
保研
腾讯云
中间件
SDRAM
unix
整周模糊度
powershell
云idea
python 技巧
客快物流大数据项目
皮卡丘
ioc
信号维度
conda
Java并发
按键
C++语法,动态绑定
多模态
弹性伸缩
GPU
2024/4/11 22:21:48
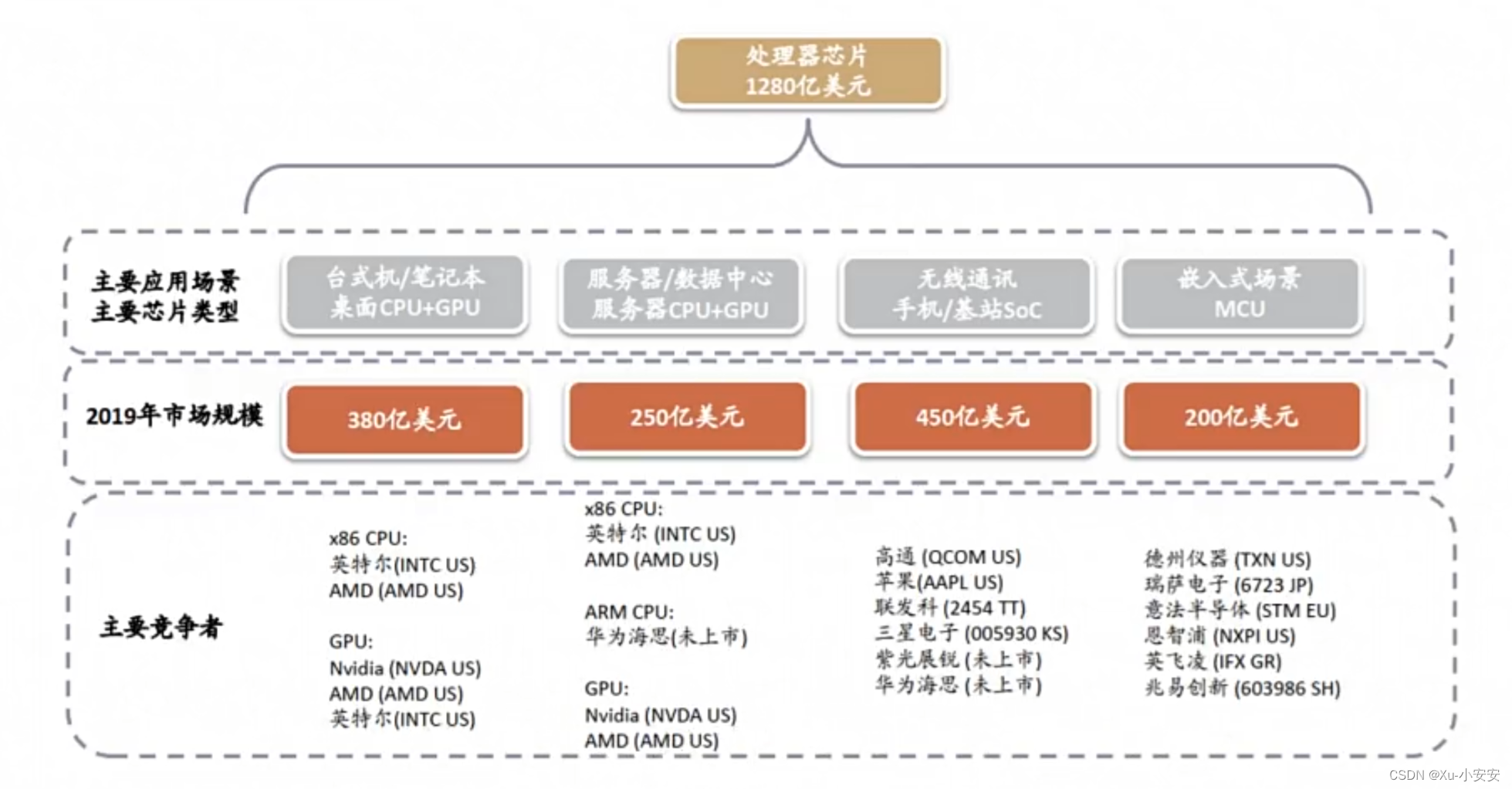
小白也能看懂的国内外 AI 芯片概述
随着越来越多的企业将人工智能应用于其产品,AI芯片需求快速增长,市场规模增长显著。因此,本文主要针对目前市场上的AI芯片厂商及其产品进行简要概述。
简介
AI芯片也被称为AI加速器或计算卡,从广义上讲只要能够运行人工智能算法…
最新版TensorFlow的GPU版本不支持原生Windows系统(大坑预警)
一、前言
首先需要说明,按照官方中文文档安装是无法正常检测到GPU的。因为TensorFlow 2.10是支持原生Windows系统GPU环境的最后版本,默认安装的版本都比较高。
中文文档没有说明,英文文档是有提到的: (我在GitHub上找…
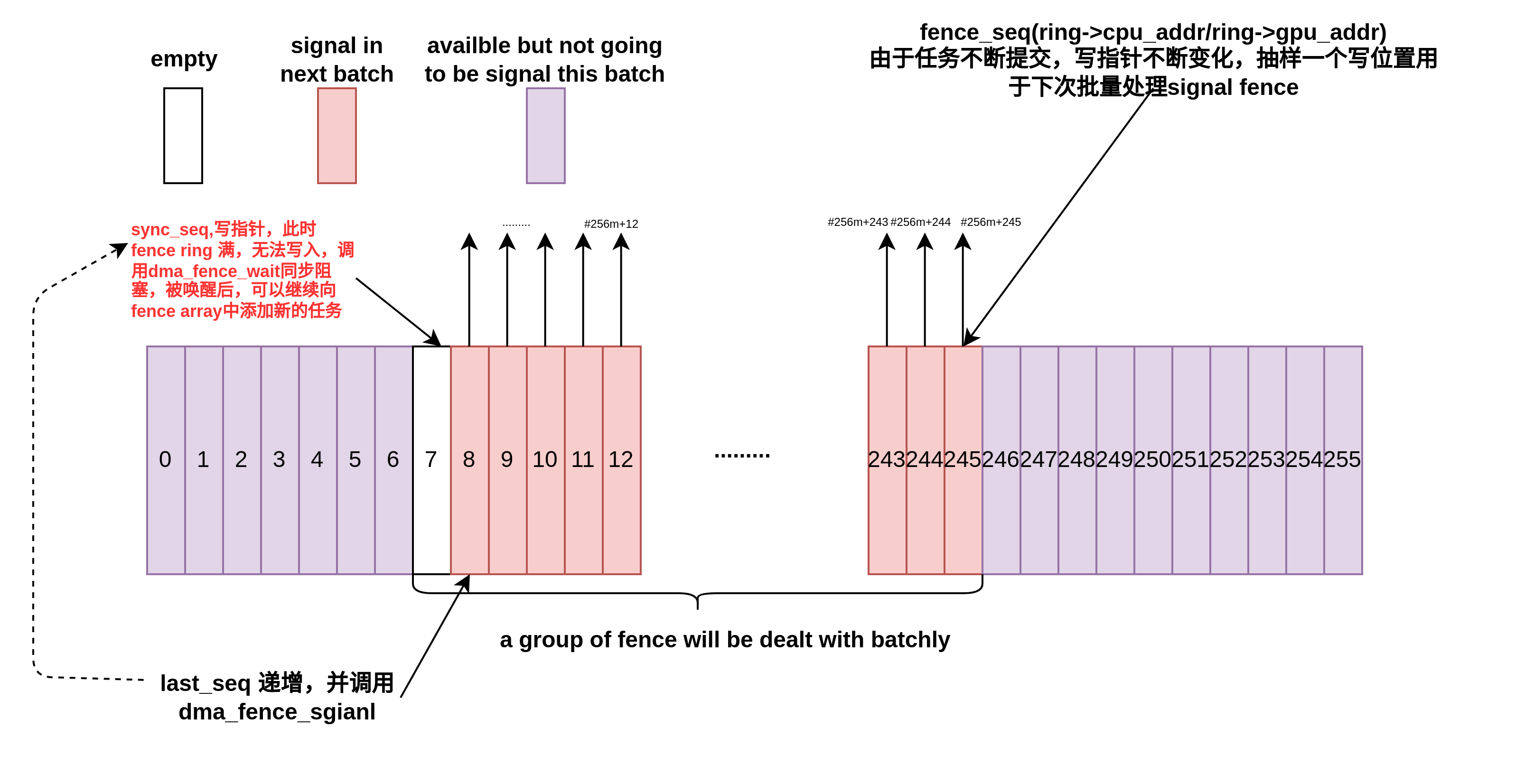
AMD GPU 内核驱动分析(三)-dma-fence 同步工作模型
在Linux Kernel 的AMDGPU驱动实现中,dma-fence扮演着重要角色,AMDGPU的Render/解码操作可能涉及到多个方面同时引用buffer的情况,以渲染/视频解码场景为例,应用将渲染/解码命令写入和GPU共享的BUFFER之后,需要将任务提…

浅谈PBR在手游开发中的适用性
原文链接:https://blog.uwa4d.com/archives/TechSharing_109.html这是第109篇UWA技术知识分享的推送。今天我们继续为大家精选了若干和开发、优化相关的问题,建议阅读时间15分钟,认真读完必有收获。
UWA 问答社区:answer.uwa4d.co…

移动端GPU性能深度优化分析
对于开发一款游戏,大多数的开发人员仅仅停留在会使用Unity提供的组件来做游戏开发,至于这些组件的底层是什么?渲染队列、深度写入以及Overdraw这些涉及到GPU的名词到底是什么?如何根据GPU性能指标来调优?这些基本上对于…
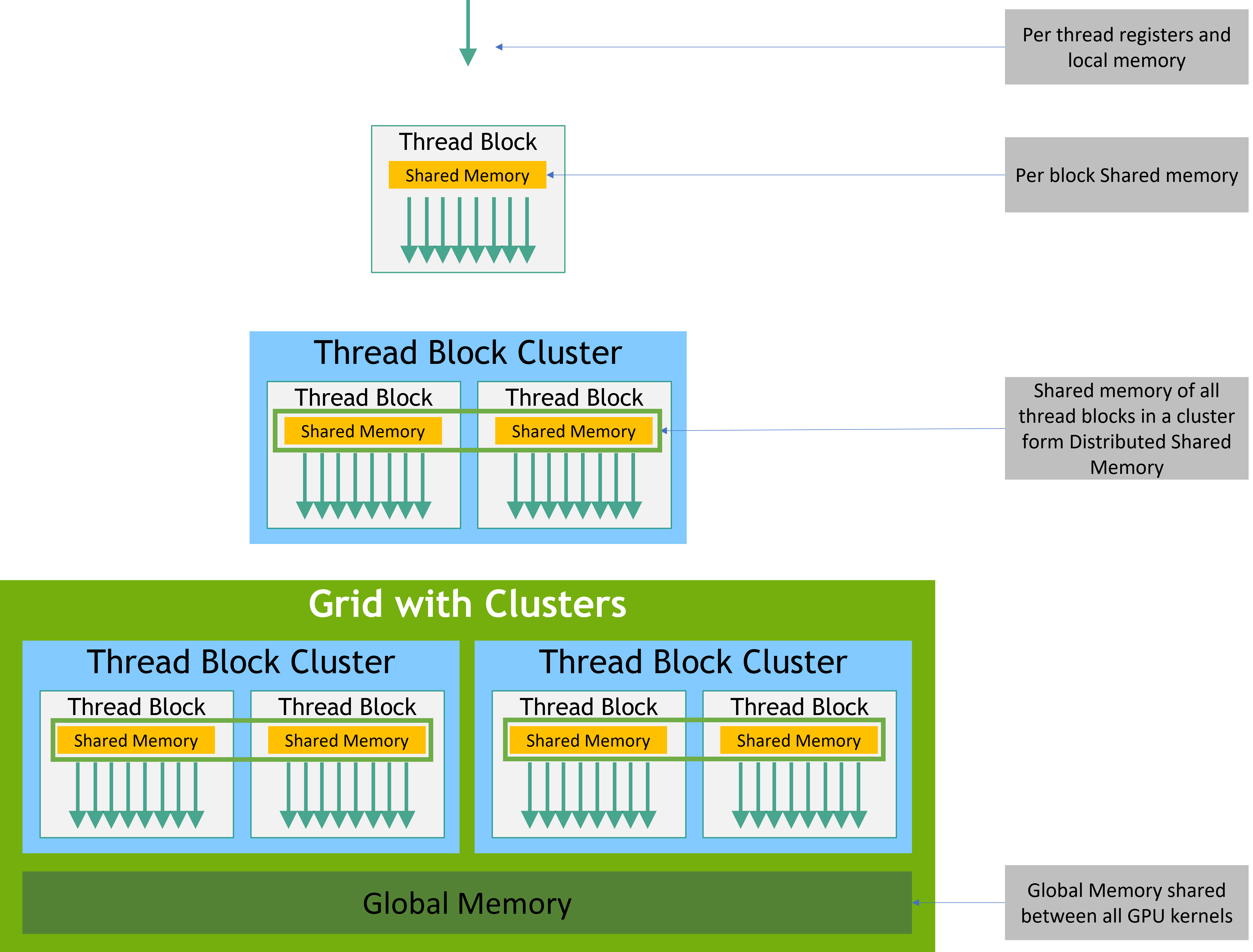
极智开发 | CUDA线程模型与全局索引计算方式
欢迎关注我的公众号 [极智视界],获取我的更多经验分享
大家好,我是极智视界,本文分享一下 CUDA线程全局索引计算方式。 邀您加入我的知识星球「极智视界」,星球内有超多好玩的项目实战源码和资源下载,链接:https://t.zsxq.com/0aiNxERDq CUDA 线程全局索引的计算,是很容…
【GPU编程】Visual Studio创建基于GPU编程的项目
vs创建基于GPU编程的项目 🍊前言🐸方法一-CUDA Runtime生成😝debug设置 🍅方法二-空项目配置🍉🍉🍉代码验证 🍊前言
cuda以及cudnn的安装以及系统环境变量的配置默认已经做完。如果…
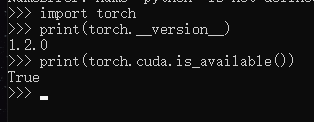
老电脑安装pytorch一直显示Your installed CUDA driver is:10.0
Your installed CUDA driver is:10.0
出现这个情况,就是电脑配置最高位10.0
而pytorch-gpu版本,支持10.0的只有pytorch1.2版本
高版本是不支持较低cuda的,所以只能自己在重新找个合适的版本下载了,
个人试过1.6、1.7版本的pyt…

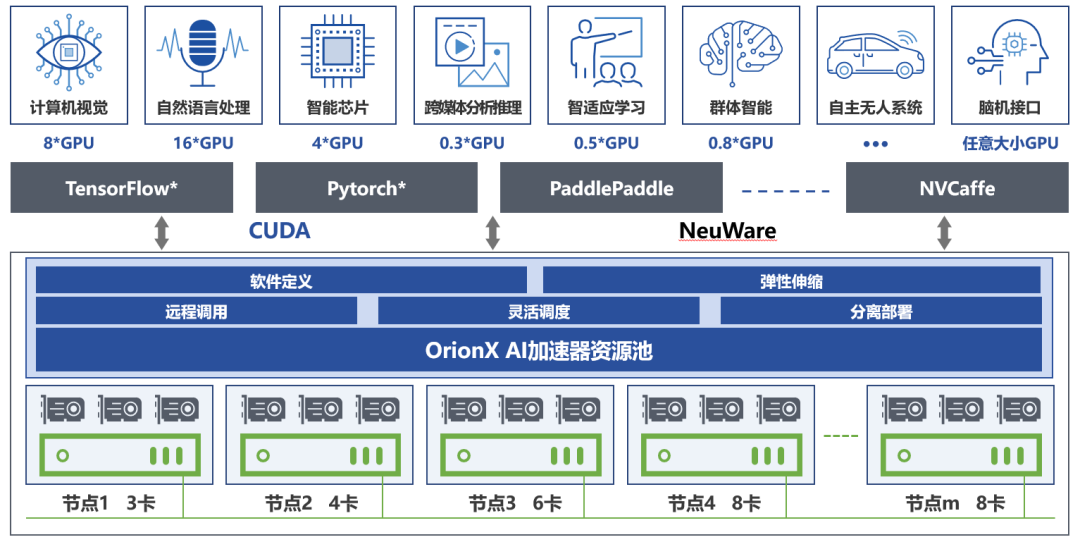
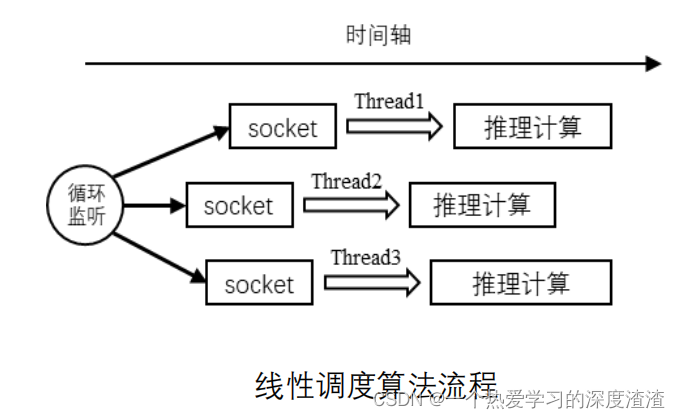
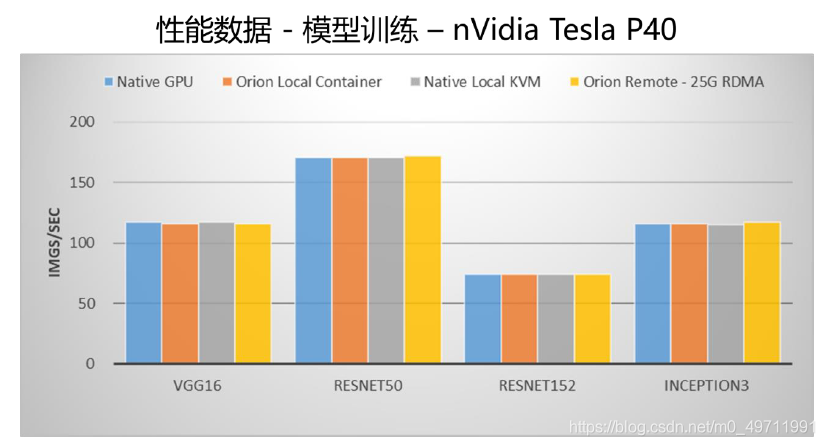
OrionX(猎户座)AI加速器资源池化软件赋能深度学习分布式训练
目录
什么是分布式训练
为什么要分布式训练
如何做分布式训练
OrionX 如何支持分布式训练 什么是分布式训练
对于机器学习/深度学习中的模型训练任务来说,算力的需求与日俱增。分布式训练采用多个计算节点,利用分布式编程的技术实现远超于单机的计算…

Ubuntu16.04 + Cuda-9.0 + Cudnn-7.1.4 + TensorFlow1.8(极其简单)
步骤
1.Ubuntu16.04 LTS 2.配置Nvidia显卡驱动 3.Cuda-9.0 4.Cudnn-7.1.4 5.TensorFlow1.8
1. Ubuntu16.04 LTS
安装Ubuntu16.04不详细说明,网上很多博客
2. 配置Nvidia显卡驱动
网上很多博客,但是我介绍一种简单的安装方法,找到"系…

CPU与GPU的区别与协作
CPU和GPU区别以及如何协同工作
CPU是Central Processing Unit的缩写,意思是中央处理器,它是计算机的核心部件,负责执行各种程序和指令,处理各种数据和逻辑。CPU通常由控制单元、运算单元、寄存器、缓存等组成,它可以根…
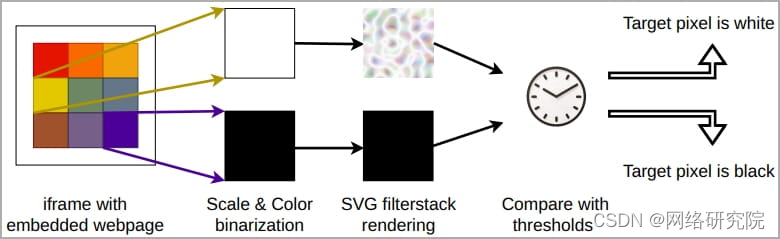
现代 GPU 容易受到新 GPU.zip 侧通道攻击
来自四所美国大学的研究人员开发了一种新的 GPU 侧通道攻击,该攻击利用数据压缩在访问网页时泄露现代显卡中的敏感视觉数据。
研究人员通过 Chrome 浏览器执行跨源 SVG 过滤器像素窃取攻击,证明了这种“ GPU.zip ”攻击的有效性。
研究人员于 2023 年 …
CUDA编程(四)并行化我们的程序
CUDA编程(四)
CUDA编程(四)并行化我们的程序
上一篇博客主要讲解了怎么去获取核函数执行的准确时间,以及如何去根据这个时间评估CUDA程序的表现,也就是推算所谓的内存带宽,博客的最后我们计算…

Python与GPU编程快速入门(二)
Python与GPU编程快速入门 文章目录 Python与GPU编程快速入门2、将GPU与CuPy结合使用2.1 CuPy介绍2.2 Python中的卷积2.3 使用SciPy在CPU上进行卷积2.4 使用CuPy在GPU上进行卷积2.5 测量性能2.6 验证2.7 在 GPU 上执行 NumPy 例程本文将详细介绍如何在Python中使用CUDA,从而使P…
游戏中动态分辨率从原理到应用
序 随着当前越来越多的手游向“3A”靠拢,手机上的各种性能优化也在努力地为“3A”保驾护航,恨不得要把芯片上每一个晶体管的性能都挖掘出来。但是,当一台“高分低能”的手机摆在你面前的时候,是不是总是有一种“欲哭无泪”的无力感…

Windows安装GPU版本的pytorch详细教程
文章目录 chatGLM2-6B安装教程正式安装 chatGLM2-6B
ChatGLM2-6B版本要装pytorch2.0,而且要2.0.1 ,因此CUDA不能用12.0 ,也不能用10.0,只能用11.x 版本。
安装教程
pip install直接下载安装 官网: https://pytorch.…

Tensorflow 、Pytorch测试GPU、CUDA是否可用
Tensorflow 测试GPU是否可用
1.打开Anconda Prompt进入环境
conda activate tf //激活环境名为tf的环境2.输入python,进入python 3.输入测试代码
import tensorflow as tf
print(tf.test.is_gpu_available())4.打印结果
True //表示GPU可用
False//表示GPU不可…
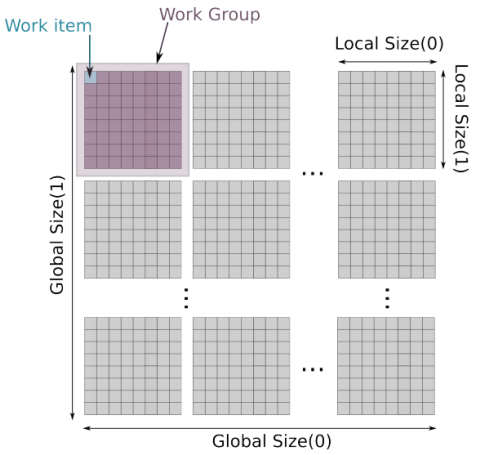
性能优化-OpenCL 介绍
「发表于知乎专栏《移动端算法优化》」 本文首先对 GPU 进行了概述,然后着重地对移动端的 GPU 进行了分析,随后我们又详细地介绍了 OpenCL 的背景知识和 OpenCL 的四大编程模型。希望能帮助大家更好地进行移动端高性能代码的开发。 🎬个人简介…

pycharm 调试代码使用远程 GPU 上面的 python解释器
文章目录pycharm 调试代码使用远程 GPU 上面的 python解释器一、配置远程 GPU 服务器的连接二、配置远程GPU服务器上的 python 解释器三、查看同步文件参考资料pycharm 调试代码使用远程 GPU 上面的 python解释器
一、配置远程 GPU 服务器的连接
配置服务器连接信息ÿ…
GPU池化在AI OCR场景的应用
一、AI OCR的历史及概念
OCR(Optical Character Recognition,光学字符识别)是指采用光学的方式将纸质文档中的文字转换成为黑白点阵的图像文件,通过检测暗、亮的模式确定其形状,然后用字符识别方法将形状翻译成计算机…

聊聊GPU集群网络优化
目录
1、高性能
①提升单机网络接入带宽 ②应用RDMA网络
③减少网络拥塞 ④通信算法优化
2、大规模
①可伸缩网络架构
②计算与存储分离 3、高可用
4、总结 在上一篇《聊聊GPU通信那些事》中,我们谈到了支持GPU通信的一些关键技术要点。
接下来,…

V100 GPU服务器安装GPU驱动教程
大家好,我是爱编程的喵喵。双985硕士毕业,现担任全栈工程师一职,热衷于将数据思维应用到工作与生活中。从事机器学习以及相关的前后端开发工作。曾在阿里云、科大讯飞、CCF等比赛获得多次Top名次。现为CSDN博客专家、人工智能领域优质创作者。喜欢通过博客创作的方式对所学的…
为python安装pycuda模块让GPU加速numpy的运算
直接用pip来安装就好,pip install pycuda
pycuda的使用请参考官方教程:https://documen.tician.de/pycuda/ 这里要说的是安装过程出现的问题,首先,可能会遇到gcc版本问题,这时候要确保gcc和g是用的是同一个版本&#…
Caffe2移动端GPU支持列表
移动端是Caffe2是发力的方向之一。Caffe2支持通过OpenGL调用移动GPU。然而移动端GPU却无法保持桌面上对CPU的优势,多CPU核心配弱GPU更是安卓界的一大特色。即使强大如iPhone,对于iPhone 6s以下的设备,NNPACK加速的CPU实现也比Apple的MPSCNNCo…
centos gpu 编译安装 lightgbm,安装出现问题首先考虑是否是版本对应问题
文章目录centos gpu 编译安装 lightgbm一、前置依赖:编译安装步骤:centos gpu 编译安装 lightgbm
一、前置依赖:
CMakeopenCLboost
编译安装步骤:
参考: https://blog.csdn.net/xueqinmax/article/details/1034810…

Jupyter算法开发场景GPU虚拟化的最佳实践
目录
Jupyter介绍
Jupyter开发中GPU资源传统使用模式
Jupyter开发中OrionX vGPU资源创新使用
趋动科技OrionX猎户座AI加速器资源池化解决方案 Jupyter介绍
Jupyter是当前在算法开发中非常受欢迎的交互式分析软件,它提供了一个环境,用户可以在其中记…
![记录 | docker报错could not select device driver ““ with capabilities: [[gpu]].](https://img-blog.csdnimg.cn/direct/6a1c2565ac8941c1a3dfb88048d29d20.png#pic_center)
记录 | docker报错could not select device driver ““ with capabilities: [[gpu]].
ubuntu18.04 上启动 docker start 报错: could not select device driver “” with capabilities: [[gpu]]. docker: Error response from daemon: could not select device driver “” with capabilities: [[gpu]]. ERRO[0005] error waiting for container: con…
极智芯 | 解读国产AI算力算能产品矩阵
欢迎关注我的公众号 [极智视界],获取我的更多经验分享
大家好,我是极智视界,本文分享一下 解读国产AI算力 华为昇腾产品矩阵。 邀您加入我的知识星球「极智视界」,星球内有超多好玩的项目实战源码和资源下载,链接:https://t.zsxq.com/0aiNxERDq 算能属于自研 TPU 阵营,…

tensorflow多gpu能训练更大尺寸的图片数据集么?
比如我544*544的单卡2080ti训练,就会占满整个显存,要是图像再大点就会爆显存。这时候就有人会想租更大显存的gpu,可是tf1.x版本的只支持20系列及以下配制的gpu训练,30系列显卡在tf1.x上是用不了gpu的,所以只能用2080ti…
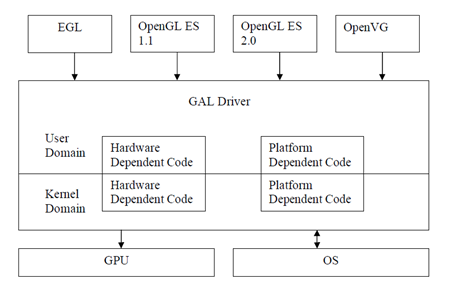
Vivante GPU简介
************************************************************************************************************************************************
Vivante 百度百科
Vivante是嵌入式图形处理器(GPU)设计领域中的技术先行者。
中文名 图芯…
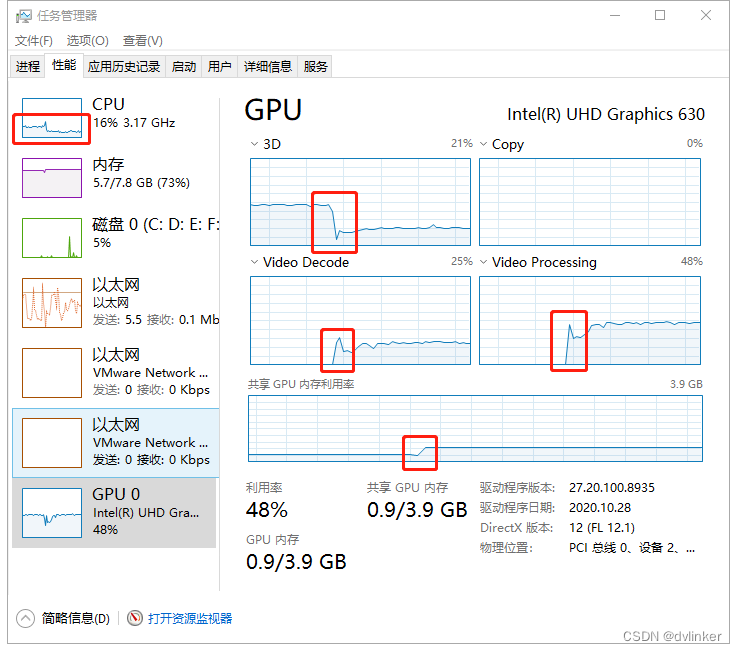
使用PotPlayer播放器查看软解和硬解4K高清视频时的CPU及GPU占用情况
目录
1、问题说明
2、PotPlayer播放器介绍
3、视频的软解与硬解
4、使用PotPlayer查看4K高清视频软解和硬解时的CPU占用情况
4.1、使用软解时CPU和GPU占用情况
4.2、使用硬解时CPU和GPU占用情况
5、最后 VC常用功能开发汇总(专栏文章列表,欢迎订阅…
cuda c源代码-1
记录下学习cuda过程中的源代码,附有注释以便回顾学习。
#include <iostream>
using namespace std;__global__ void add(int a, int b, int *c) {*c a b;
}int test1(void) { // 设备指针和生成设备内存int c;int *dev_c;cudaMalloc((void**)&dev_c, s…

【NVIDIA CUDA】2023 CUDA夏令营编程模型(三)
博主未授权任何人或组织机构转载博主任何原创文章,感谢各位对原创的支持! 博主链接 本人就职于国际知名终端厂商,负责modem芯片研发。 在5G早期负责终端数据业务层、核心网相关的开发工作,目前牵头6G算力网络技术标准研究。 博客…

【NVIDIA】Ubuntu18.04安装CUDA-9.0 (已安装CUDA-10.0, CUDNN-7.3.0)
GCC, G版本降级: 由于CUDA 9.0仅支持GCC 6.0及以下版本,而Ubuntu 18.04预装GCC版本为7.3,故手动安装gcc-5与g-5:
sudo apt-get install gcc-5
sudo apt-get install g-5sudo update-alternatives --install /usr/bin/gcc gcc /us…

NVIDIA NCCL 源码学习(十二)- double binary tree
上节我们以ring allreduce为例看到了集合通信的过程,但是随着训练任务中使用的gpu个数的扩展,ring allreduce的延迟会线性增长,为了解决这个问题,NCCL引入了tree算法,即double binary tree。
double binary tree
朴素…
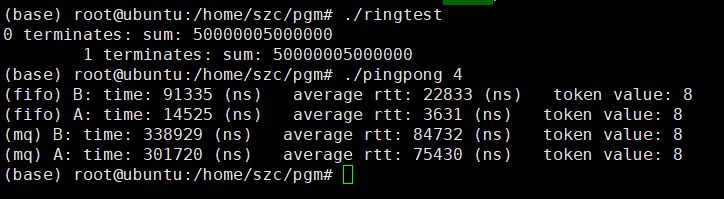

深入UGUI Mask组件原理和性能深度优化
对于一款游戏UI系统必不可少,UGUI是现在项目组中实现UI系统的大多数解决方案,使用广泛。UGUI提供的组件很多,外部很多厂商也提供了很多UGUI的第三方插件,而客户端开发人员往往过度关注项目进度实现功能,对各个组件仅仅…

DeepStream User Guide
目录布局
DeepStream SDK包含两个主要部分:库和工作流演示示例。已安装的DeepStream软件包包括目录/lib,/include,/doc和/samples。
动态库libdeepstream.so位于/lib目录中有两个头文件:deepStream.h和module.h deepStream.h包括…

使用TVM优化深度学习GPU算子:深度卷积实例
以下内容翻译自:Optimize Deep Learning GPU Operators with TVM: A Depthwise Convolution Example 高效的深度学习算子是深度学习系统的核心。通常这些算子很难优化,并且需要高性能计算专家的努力。TVM,端到端张量IR/DSL堆栈,使…
NVIDIA Tesla/Quadro和GeForce GPU比较
英伟达gtx不仅可以用来玩游戏,就深度学习任务而言,gtx具备的算力并不亚于tesla专业显卡。并且,游戏卡的价格相比专业卡要便宜不少。那么二者之间的差异是什么呢? 首先,gtx的单卡计算性能和tesla差别不大。虽然英伟达大…
DeepStream: 新一代智能城市视频分析
以下主体内容翻译自:DeepStream: Next-Generation Video Analytics for Smart Cities 试想一下每个家长最糟糕的噩梦:一个孩子在拥挤的商场里迷路。现在想象一下,建筑物内部署的摄像机网络在几分钟之内就可以找到这个孩子的位置,并…
linux(GPU)查看服务器配置
一、服务器型号
命令: cat /etc/redhat-release
二、CPU
命令: 查看CPU统计信息:lscpu查看CPU型号:cat /proc/cpuinfo | grep name | cut -f2 -d: | uniq -c查看物理CPU个数:cat /proc/cpuinfo| grep “physical id…
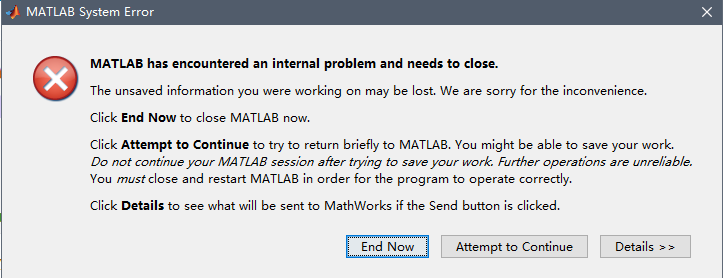
Matlab System Error
参考官方说明Why does MATLAB crash when plotting with AMD drivers? 安装驱动管家检测显卡驱动是否已经过时更新Intel显卡驱动到最新版本更新AMD显卡驱动(我的是AMD,你的可能是其他的如NVIDIA)重新启动电脑
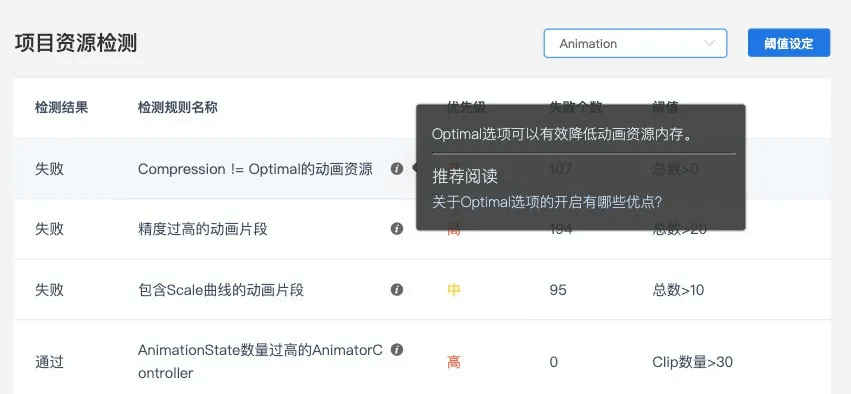
Unity性能优化 — 动画模块
我们曾在四年前对于Unity的主流模块的性能优化知识点逐一做过讲解,俗称“小白版”。随着这几年引擎本身、硬件设备、制作标准等等的升级,UWA也不断更新优化规则和方法并持续输出给广大开发者。作为"升级版"的性能优化手册,【Unity性…
如何在 ubuntu 下安装英伟达 GPU 的驱动程序?
在 Ubuntu 下安装 NVIDIA GPU 驱动程序的方法如下: 打开终端,并检查您的 GPU 型号:lspci | grep -i nvidia。如果您已经知道您的 GPU 型号,可以跳过此步。 添加 NVIDIA 的软件源。 首先,确认您的系统已经安装了 Secur…
opencv 3.0 LUT GPU加速
opencv 自带了一个查找表函数,可以实现并行快速查找的运算。有GPU加速功能 void LUT_test()
{Mat lookUpTable(1, 256, CV_8U);uchar *ptr lookUpTable.data;for (int i0; i<256; i)ptr[i] (i >> 1) << 1; //color reducecout << lookUpTa…
使用动态参数构建CUDA图
文章目录使用动态参数构建CUDA图使用显式 API 调用构建 CUDA 图使用流捕获构建 CUDA 图组合方法执行结果总结使用动态参数构建CUDA图
自从在 CUDA 10 以来,CUDA Graphs 已被用于各种应用程序。 上图将一组 CUDA 内核和其他 CUDA 操作组合在一起,并使用指…

print(torch.cuda.is_available()) False如何解决?GTX3090
首先介绍环境: 保证Cuda与Pytorch的版本对齐就可以了。
nvcc -V 查看原来装的是cuda11.3版本
去Pytorch官网找到相应指令下载即可: CtrlF:cuda11.3 就在诸多版本中找到啦,一定找 torch的版本cuda版本。我之前错误安装的torch,只…

win10安装Tensorflow(2.10-)使用最新cuda(12+),cudnn(8.9+)
# tensorflow在2.11版本后不再支持原生windows的GPU:
https://blog.tensorflow.org/2022/09/whats-new-in-tensorflow-210.html# 1、首先,在windows安装好最新的GPU环境:
https://blog.csdn.net/sinat_20174131/article/details/121781420?s…
【Soc级系统防御】基于IP的SoC设计中的安全问题
文章目录 Perface硬件知识产权(IP)基于 IP 的 SoC 设计中的安全问题硬件木马攻击攻击模式知识产权盗版和过度生产攻击模式逆向工程集成电路逆向工程示例Fpga 的安全问题FPGA 预演基于 FPGA 的系统的生命周期实体生命周期对 FPGA 比特流的攻击

深度学习技巧应用30-深度学习中的GPU的基本架构原理与应用技巧
大家好,我是微学AI,今天给大家介绍一下深度学习技巧应用30-深度学习中的GPU的基本架构原理与应用技巧,GPU是一种专门用于处理大量并行操作的硬件设备,它的架构设计主要是为了图形渲染。然而,由于其并行处理能力,现在广泛应用于深度学习、科学计算等领域。主要的GPU制造商…
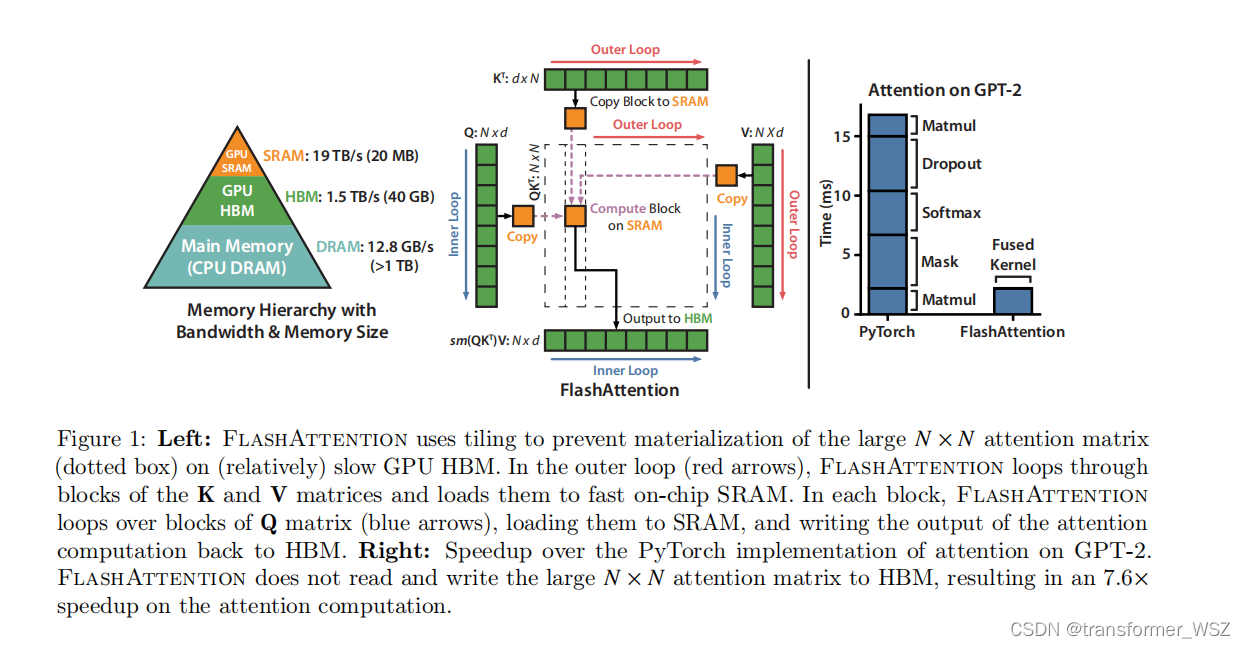
Flash-Attention
这是一篇硬核的优化Transformer的工作。众所周知,Transformer模型的计算量和储存复杂度是 O ( N 2 ) O(N^2) O(N2) 。尽管先前有了大量的优化工作,比如LongFormer、Sparse Transformer、Reformer等等,一定程度上减轻了Transformer的资源消耗…
Python与GPU编程快速入门(一)
Python与GPU编程快速入门 文章目录 Python与GPU编程快速入门1、图形处理单元(Graphics Processing Unit,GPU)1.1 并行设计1.2 速度优势本系列文章将详细介绍如何在Python中使用CUDA,从而使Python应用程序加速。 1、图形处理单元(Graphics Processing Unit,GPU)
图形处理…

TensorFlow指定GPU使用及监控GPU占用情况
查看机器上GPU情况
命令: nvidia-smi
功能:显示机器上gpu的情况
命令: nvidia-smi -l
功能:定时更新显示机器上gpu的情况
命令:watch -n 3 nvidia-smi
功能:设定刷新时间(秒)显…
Ubuntu离线安装Pytorch和torchvision
Ubuntu离线安装Pytorch和torchvision
首先明确torch和torchvision的对应依赖版本
torchtorchvisionpythoncuda1.510.61>3.610.1,10.21.500.6.0>3.610.1,10.21.4.00,5.0>3.5,<3.89.2,10.01.3.10.4.2>3.5ÿ…

CPU和GPU的设计区别
CPU和GPU之所以大不相同,是由于其设计目标的不同,它们分别针对了两种不同的应用场景。CPU需要很强的通用性来处理各种不同的数据类型,同时又要逻辑判断又会引入大量的分支跳转和中断的处理。这些都使得CPU的内部结构异常复杂。而GPU面对的则是…

问题记录:GPU显卡提高后,代码总体运行效率没有提高
问题:GPU显卡提高后,代码总体运行效率没有提高
原先显卡NIVIDA T400换成NVIDIA RTX A4000,CUDA核心(物理GPU线程单位)从三百多提升到了六千多,但是程序总体运行的时间没有变化。
原因分析
显卡没用上或者…

GPU Microarch 学习笔记【2】Unified Memory
目录
1. M3 Dynamic Caching
2. Unified Memory
3. Unified Memory是如何处理page fault的
4. Unified Memory Page Fault的相关论文 M3 Dynamic Caching 最新的Apple M3 芯片最亮眼的可能是支持dynamic caching,如下图所示。 具体说来就是传统的GPU分配内存时&…
Ubuntu17.10 为dlib库加速:使用GPU运算
首先,安装确保你有一块支持CUDA的GPU,可以看我写的文章:http://blog.csdn.net/qq_34877350/article/details/78528957
然后装cuDNN,可以看我写的文章:http://blog.csdn.net/qq_34877350/article/details/78554650 …
基于OpenGL的滤镜架构搭建(IOS)
最近为别的项目组写了一个基于OpenGL的实时滤镜架构,感觉还是挺系统的一个东西,值得记录下来。滤镜,个人理解可以说是一个对图像进行实时绘制和处理的机制,基于采集到的图像进行颜色、线条、轮廓等等的处理。在OpenGL中࿰…
pytorch学习笔记,cnn与gpu加速
cnn代码,警告见gpu版修正,版本问题。
import torch
import torch.nn as nn
import torch.utils.data as Data
import torchvision # 数据库模块
import matplotlib.pyplot as pltimport logginglogger logging.Logger(None)torch.manual_seed(1) …
机器学习硬件十年:性能变迁与趋势
本文分析了机器学习硬件性能的最新趋势,重点关注不同GPU和加速器的计算性能、内存、互连带宽、性价比和能效等指标。这篇分析旨在提供关于ML硬件能力及其瓶颈的全面视图。本文作者来自调研机构Epoch,致力于研究AI发展轨迹与治理的关键问题和趋势。 &…

对比脉动架构、TPUNvidia、GPU tensorcore
1.CPU和GPU
CPU(CentralProcessing Unit)中央处理器,是一块超大规模的集成电路,主要逻辑架构包括控制单元Control,运算单元ALU和高速缓冲存储器(Cache)及实现它们之间联系的数据(Da…

GPU性能实时监测的实用工具
大家好,我是爱编程的喵喵。双985硕士毕业,现担任全栈工程师一职,热衷于将数据思维应用到工作与生活中。从事机器学习以及相关的前后端开发工作。曾在阿里云、科大讯飞、CCF等比赛获得多次Top名次。现为CSDN博客专家、人工智能领域优质创作者。喜欢通过博客创作的方式对所学的…
Python与GPU编程快速入门(三)
3、使用Numba加速Python代码
Numba 是一个 Python 库,它使用行业标准 LLVM 编译器库在运行时将 Python 函数转换为优化的机器代码。 您可能想尝试用它来加速 CPU 上的代码。 然而,Numba还可以将Python 语言的子集转换为CUDA,这就是我们将在这里使用的。 所以我们的想法是,…
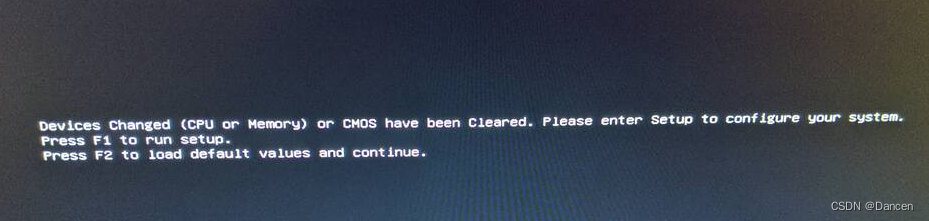
有关GPU主机的一些故障
问题1. GPU主机执行nvidia-smi命令失败 主机A是一台新购的GPU主机,在该主机上执行nvidia-smi命令报错:
NVIDIA-SMI has failed because it couldnt communicate with the NVIDIA driver.
Make sure that the latest NVIDIA driver is installed and ru…

使用 Docker Client 和 Go SDK 为容器分配 GPU 资源
❝本文转自博客园,原文:https://www.cnblogs.com/joexu01/p/16539619.html,版权归原作者所有。欢迎投稿,投稿请添加微信好友:cloud-native-yang背景深度学习的环境配置通常是一项比较麻烦的工作,尤其是在多…
ARM和X86、X86和X64、Intel和AMD、CPU和GPU介绍
一、ARM和X86
X86 和 ARM 都是CPU设计的一个架构。X86 用的是复杂指令集。ARM用的是精简指令集。 指令集其实就是机器码,机器码上是汇编,汇编之上是程序语言例如java、c、c#。 复杂指令集是在硬件层面上设计了很多指令,所以编程会简单些。 精…
NVIDIA GPU的计算能力 Compute Capability 一览
数据出处:https://developer.nvidia.com/cuda-gpus
提示:利用浏览器的搜索功能(CtrlF),查询自身GPU的计算性能 如,想知道GTX980Ti的计算能力,在搜索框中键入:GTX 980 Ti即可&#…
failed to create cublas handle: CUBLAS_STATUS_ALLOC_FAILED 错误解决方法
如果你是使用 GPU 版 TensorFlow 的话,并且你想在显卡高占用率的情况下(比如玩游戏)训练模型,那你要注意在初始化 Session 的时候为其分配固定数量的显存,否则可能会在开始训练的时候直接报错退出:
2017-0…

CUBLAS库入门教程(从环境配置讲起)
文章目录 前言一、搭建环境二、简单介绍三、 具体例子四、疑问 前言
CUBLAS库是NVIDIA CUDA用于线性代数计算的库。使用CUBLAS库的原因是我不想去直接写核函数。 (当然,你还是得学习核函数该怎么写。但是人家写好的肯定比我自己写的更准确!&…
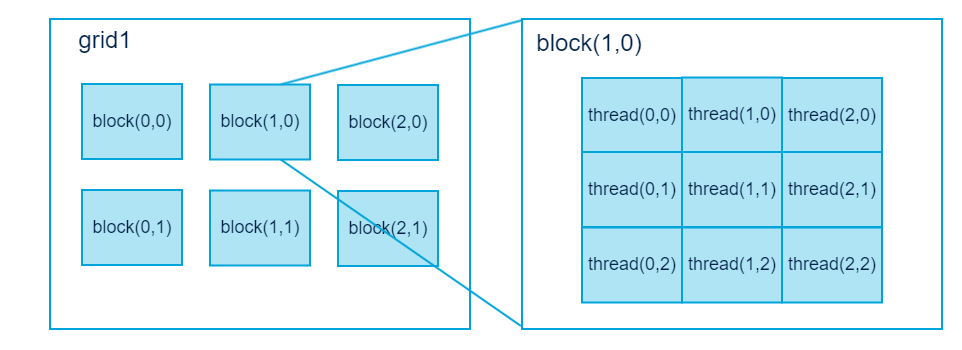
CUDA编程(一)第一个CUDA程序
CUDA编程(一)
第一个CUDA程序 Kernel.cu
CUDA是什么?
CUDA(Compute Unified Device Architecture),是显卡厂商NVIDIA推出的运算平台。是一种通用并行计算架构,该架构使GPU能够解决复杂的计算问题。说白了就是我们可…
将 Docker 踢出群聊后,Kubernetes 还能否欢快地跑 GPU?当然能!
该文章随时会有校正更新,公众号无法更新,欢迎订阅博客查看最新内容:https://fuckcloudnative.io 前言 前两天闹得沸沸扬扬的事件不知道大家有没有听说,Google 竟然将 Docker 踢出了 Kubernetes 的群聊,不带它玩了。。。…

tensorflow-gpu和Cuda、cuDNN安装成功经验(win10、无需Anaconda)
因为自己的win10笔记本上用cpu跑深度学习的训练实在是慢,想把电脑上的一块显存2G的Nvida Geforce 940mx的显卡用起来。虽然这个显卡很普通,但比cpu跑的还是快多了。(因为GPU更适合进行矩阵运算)
经过一下午的努力,一波…
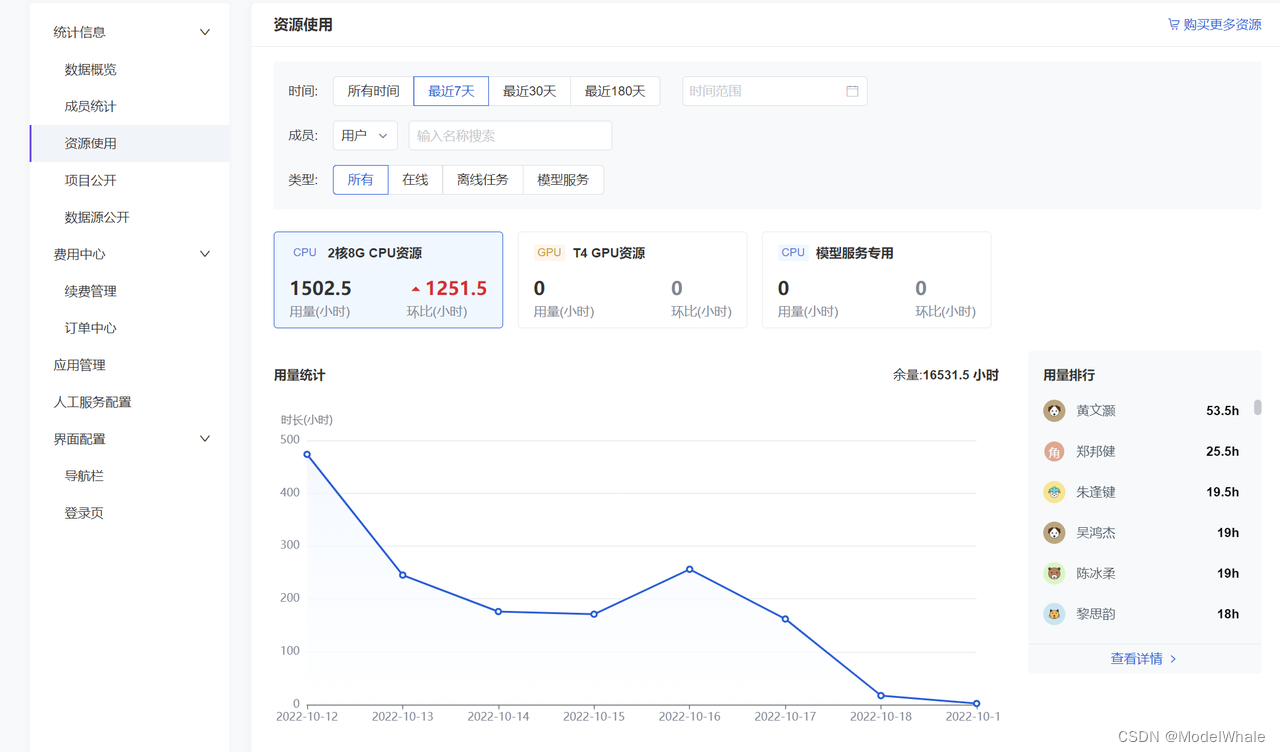
集约管控、按需分配:和鲸聚焦 AI for Science 科研算力高校调配
随着人类社会进入信息时代的智能化阶段,数据逐渐成为基础生产要素之一,而算力也因此成为重要生产力。《学习时报》9 月 3 日发文《算力为何如此重要》,文中指出,人工智能技术的突破与产业数字化应用对算力提出了更高的要求&#x…

LLM大语言模型(一):ChatGLM3-6B试用
前言
LLM大语言模型工程化,在本地搭建一套开源的LLM,方便后续的Agent等特性的研究。
本机环境
CPU:AMD Ryzen 5 3600X 6-Core Processor
Mem:32GB
GPU:RTX 4060Ti 16G
ChatGLM3代码库下载
# 下载代码库
git c…
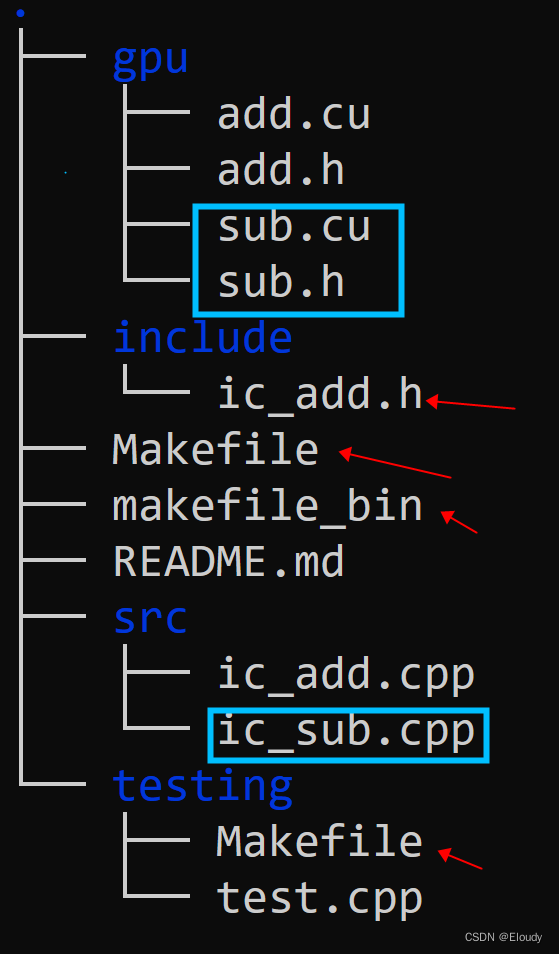
一个完整的手工构建的cuda动态链接库工程 02记
step3, 两个 API 函数的动态链接库 Makefile 版本 对比之前的文件树: 现在的文件树: 添加了3个新文件,修改了4个旧文件,其中include/ic_add.h 其实可以改成 icmm.h,作为整个 shared library 被调用的头文件。
现将新文…

Win10 Tensorflow GPU版 安装教程 超详细
Win10 Tensorflow GPU版步骤一、安装Anaconda;二、查找要安装的版本;2.1查找电脑GPU型号2.2查看Tensorflow配置三、安装CUDA 10.1;四、安装cuDNN 7.4;五、安装Tensorflow GPU六、Pycharm配置tensorflow环境一、安装Anaconda;
请先安装Anacon…
高性能计算 (HPC) 的发展趋势是什么?
随着科学、工程和商业领域对于大规模数据和复杂计算需求的不断增长,高性能计算(HPC)正成为推动技术进步和创新的关键力量。在未来,HPC将继续发展,以下是几个HPC领域的发展趋势: 更强大的硬件:高…

ubuntu16.04 安装Tensorflow(GTX980Ti+CUDA8.0+CUDNNv6.0)
如果安装过程遇到问题,可直接跳转到问题汇总查看
1.我的电脑安装环境:
双系统:win10Ubuntu16.04(在Ubuntu下配置) CPU:E5-1660 v4 GPU:GTX-980Ti
2.安装GPU版Tensorflow的官方要求
Tensorflow官方的安装要求在如下链接中可以…

编译运行hog的opencv实现
背景
前几篇LitmusRT、pgmRT等的安装就是为这里的实验做准备的,因此前置条件是编译安装好了litmusRT和pgmRT,并且当前系统内核为litmusRT
下载
克隆源码到某目录下
rootubuntu:/home/szc/cpu-gpu/openvx# git clone https://github.com/Yougmark/ope…

linux服务器如何指定gpu以及用量
1.在终端执行程序时指定GPU
CUDA_VISIBLE_DEVICES0 python your_file.py # 指定GPU集群中第一块GPU使用,其他的屏蔽掉
CUDA_VISIBLE_DEVICES1 Only device 1 will be seen CUDA_VISIBLE_DEVICES0,1 Devices 0 and 1 will be…

HPC是如何助力AI推理加速的?
高性能计算(High-Performance Computing,HPC)通过提供强大的计算能力、存储资源和网络互联,可以显著地辅助人工智能(AI)应用更快地进行训练和推断。那么,HPC是如何助力AI推理加速的?…

【智算中心】GPU是如何改变世界的
现在有市场消息表示,NVIDIA正计划减少A800 GPU的产量,以促进其更高端的H800 GPU 的销售。很显然NVIDIA是希望从H800 GPU上获得更多销售量,从中国市场获得更多利益。而且最近一段时间有传闻美国要彻底封杀AI芯片的出口,让国内甚至连…
pytorch单机多gpu训练cycleGAN模型
废话不多说,直接上代码
修改cycleGan中的代码如下
原代码
disc_H Discriminator(in_channels3).to(config.DEVICE)disc_Z Discriminator(in_channels3).to(config.DEVICE)gen_Z Generator(img_channels3, num_residuals9).to(config.DEVICE)gen_H Generator(…
新手配置tensorflow-gpu
强烈推荐使用Anaconda。
在配置tensorflow的时候分为cpu版本和gpu版本。cpu版本的配置比较简单,不做具体描述了。gpu版本的配置就涉及到cuda的安装,而cuda的安装又会涉及到电脑的显卡支持的cuda版本的问题,以及tf与cuda的版本兼容的问题&…
【NVIDIA CUDA】2023 CUDA夏令营编程模型(二)
博主未授权任何人或组织机构转载博主任何原创文章,感谢各位对原创的支持! 博主链接 本人就职于国际知名终端厂商,负责modem芯片研发。 在5G早期负责终端数据业务层、核心网相关的开发工作,目前牵头6G算力网络技术标准研究。 博客…

Gazebo GPU加速【gzserver running in GPU】
文章目录 Gazebo GPU加速1. 问题2. 解决办法2.1 本机运行 2.2 headless3. 补充3.1 如何确定的Gazebo为OpenGL渲染3.2 显卡驱动--no-opengl-files3.3 nouveau Gazebo GPU加速
1. 问题
Gazebo仿真帧率极低,fps在10以下,同时显卡驱动已安装,但…
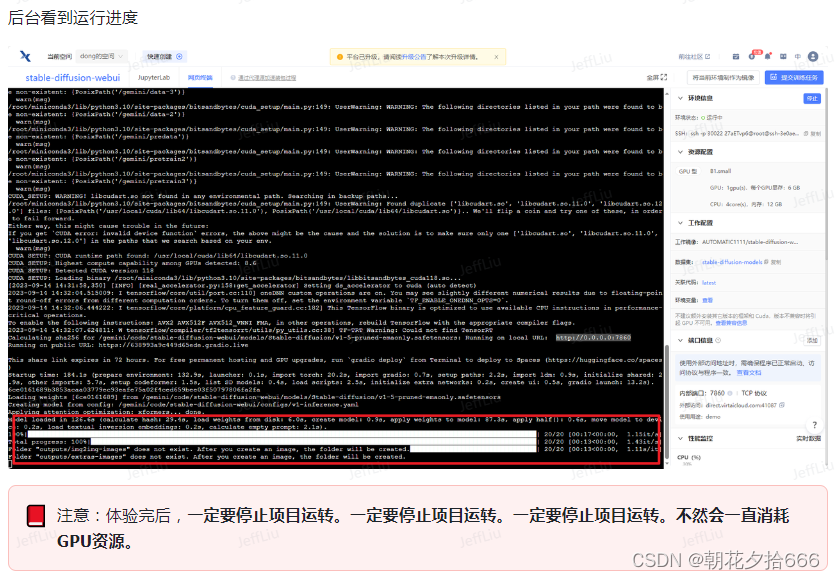
用趋动云GPU部署自己的Stable Diffusion
注:本文内容来自于对DataWhale的开源学习项目——免费GPU线上跑AI项目实践的学习,参见:Docs,引用了多处DataWhale给出的教程。
1.创建项目
1)进入趋动云用户工作台,在当前空间处选择注册时系统自动生成的…

Theano利用GPU加速
继续水文章。 以前说的直接利用sourceforge里的exe安装scipy和numpy事实上是一种比较low的方法,,哈哈。 因为安装的都是32位的,数据量一大就memoryError了,当时是在keras下跑mnist cnn时出现这个问题的。。。。 有一些更好的方法…

为什么GPU比CPU更重要
网友提问: 为什么现在更多需要用的是 GPU 而不是 CPU,比如挖矿甚至破解密码? 从煎蛋一篇文章ios热点密码不随机,破解仅需一分钟,看到提到: 不过,他们成功的原因在一定程度上也要归功于破解硬件的…

如何在kubernetes中使用共享GPU资源
目录
背景
Kubernetes如何使用物理GPU
Kubernetes如何使用共享GPU算力 背景
作为推动人工智能技术进步的“三驾马车”,算法、数据和计算力在过去的5-10年间不断创新。在算法方面,人类在机器学习的算法上实现了突破,特别是在视觉和语音技术…

狂肝10个月手搓GPU,他们在《我的世界》里面玩《我的世界》
梦晨 衡宇 萧箫 发自 凹非寺量子位 | 公众号 QbitAI自从有人在《我的世界》里用红石电路造出CPU,就流传着一个梗:总有一天,这帮红石佬能在我的世界里玩上我的世界。这一天,真的来了!先来看这台“在无MOD纯原版我的世界…

IC设计职位详解之“数字前端设计工程师”就业必学课程
数字设计处于数字IC设计流程的前端,属于数字IC设计类岗位的一种。随着芯片规模不断加大,在IC设计过程中,设计的复杂度也进一步加大,需要用到的岗位人数也越来越多。
数字设计主要分成几种层次的设计:IP level…

性能优化-OpenCL运行时API介绍
「发表于知乎专栏《移动端算法优化》」 本文首先给出 OpenCL 运行时 API 的整体编程流程图,然后针对每一步介绍使用的运行时 API,讲解 API 参数,并给出编程运行实例。总结运行时 API 使用的注意事项。最后展示基于 OpenCL 的图像转置代码。在…

GPU资源池化对金融行业的价值
目录 金融科技发展的三个阶段 智能金融的四项技术 人工智能与金融融合过程中的三大要素―数据、算力和算法 金融行业主要的落地场景 金融客户使用GPU使用现状 趋动科技OrionX猎户座AI加速器资源池化解决方案 GPU资源池化的价值: 金融科技发展的三个阶段 金融发展史是…

KVM虚拟机使用GPU的最佳实践
系统虚拟化是指一台物理计算机系统虚拟化为一台或多台虚拟计算机系统。每个虚拟机都拥有由自己的虚拟硬件提供的一个独立的虚拟机执行环境。通过虚拟化层VMM(Virtual Machine Manager)的模拟,虚拟机中的操作系统认为自己仍然独占一个系统在运…

LLVM AMDGPU 后端代码分析研究(1):PassPipe Line
本系列文章是对GPU LLVM后端的探索与学习,后端的学习资料主要有LLVM源码和公开的Spec. 众所周知,在PC GPU领域的玩家主要有三家公司:NV, AMD, INTEL. 在LLVM 后端开源的代码只有NV, AMD,而AMD相对NV的文档分享会更Open一些&#x…
![Ubuntu系统查看显卡型号返回NVIDIA Corporation [10DE:1F97]](https://img-blog.csdnimg.cn/4629379881664d4b80facaf6aee838d6.png?x-oss-process=image/watermark,type_ZHJvaWRzYW5zZmFsbGJhY2s,shadow_50,text_Q1NETiBAbG9tZV8zMDIz,size_20,color_FFFFFF,t_70,g_se,x_16)
Ubuntu系统查看显卡型号返回NVIDIA Corporation [10DE:1F97]
因Ubuntu系统安装nvidia驱动后(通过ubuntu自带的软件 更新以及通过PPA源时也是失败的)导致无法进入登陆界面,怀疑是版本不对应导致,故打算从官网下载对应的包去安装。
手动安装invidia驱动时,需要我们先查询自己的显卡…
用sudo配置GPU MPS,docker里面没效果
# 启动
export CUDA_VISIBLE_DEVICES0 # 这里以GPU0为例,其他卡类似
nvidia-smi -i 0 -c EXCLUSIVE_PROCESS # 让GPU0变为独享模式。
nvidia-cuda-mps-control -d # 开启mps服务
# 查看
ps -ef | grep mps # 启动成功…
CUDA for循环计算递归函数,以勒让德多项式(Legendre polynomial)为例(3)
legendre_p.cu
#include "cuda_runtime.h"
#include <cuda.h>
#include <stdlib.h>
#include <iostream>
#include <sys/time.h>
#include <chrono>#define M 1000000 // M个点等分[-1, 1]
#define N 100 // Legendre polynomial…
Intel CPU指令集以及运算加速
前沿 人工智能运算分析依赖CPU和显卡的运算能力 。查询CPU支持的指令集,当前加速会用到AVX2指令集,如何查询是否支持 工具下载
https://www.cpuid.com/softwares/cpu-z.html
AMD Ryzen Threadripper 3000 preliminary support Intel Ice-Lake preliminary support…
CUDA编程(三)评估CUDA程序的表现
CUDA编程(三)
评估CUDA程序的表现
上一篇博客我们基本上搭建起来了CUDA程序的骨架,但是其中并没有涉及到我们之前不断提到的并行加速,毕竟只有当我们的程序高并行的运行在GPU上才能大大缩短运行时间。不过在加速之前我们还有一件…
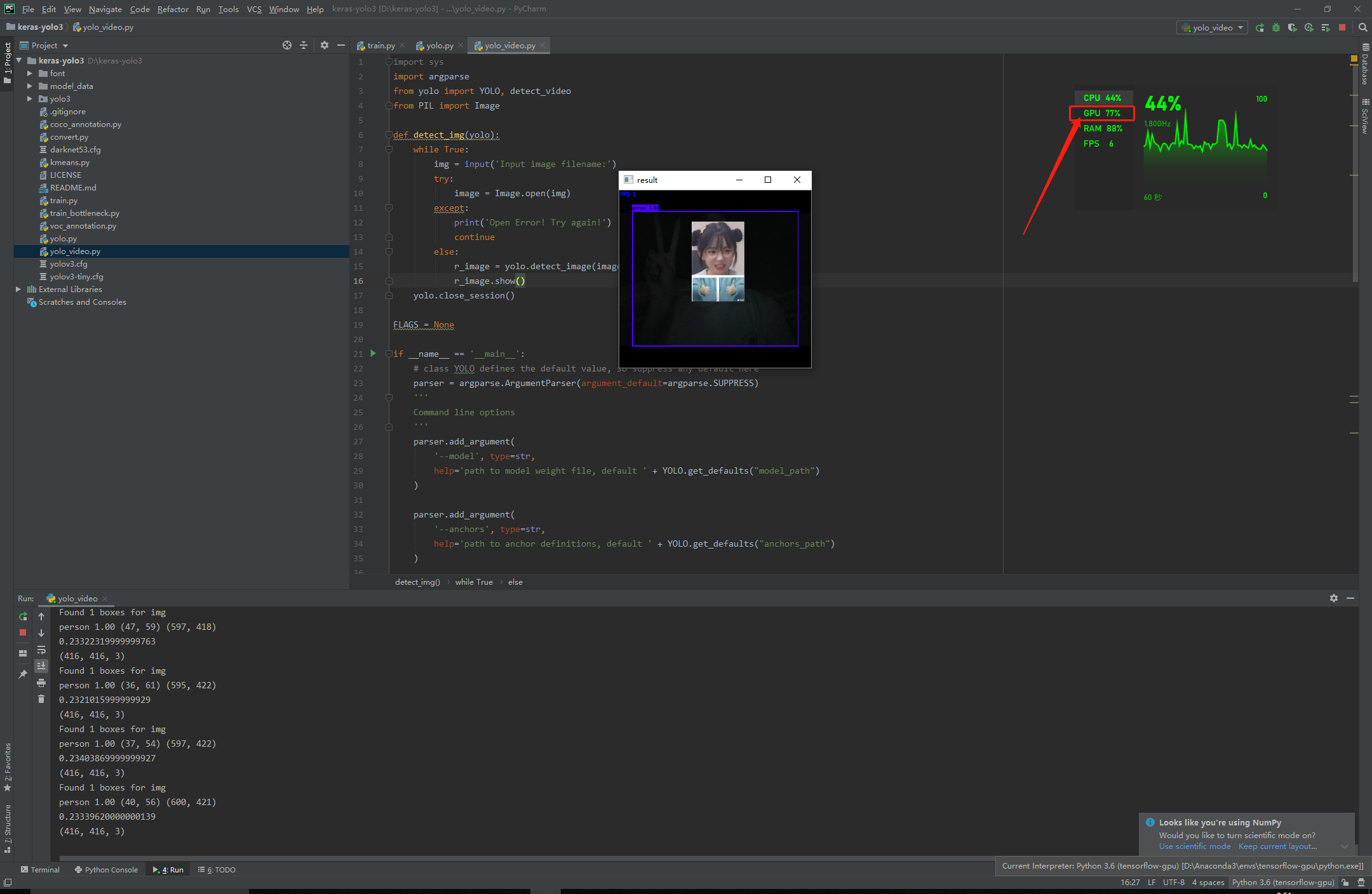
【学习笔记】windows10+tensorflow-gpu环境搭建
经过上个学期在学校和年初在家的失败后,本来没打算在自己笔记本上整的了,就怕到时候又重装,emmmm😑
本来想回到学校用实验室的电脑,不过现在这样回到学校还要好久,所以无奈之下还是装了,既然一…

高性能计算培训价格 零基础入门 从入门到精通
大模型一出,各类企业的各类“模型”竞赛般的亮家伙,算力时代抢先到来。2023年4月超算互联网的正式部署,标志着,很快,越来越多的应用都需要巨大的计算资源。 这给传统的计算机体系结构带来了巨大的挑战,计算…

#GPU|LLM|AIGC#集成显卡与独立显卡|显卡在深度学习中的选择与LLM GPU推荐
区别
核心区别:显存,也被称作帧缓存。独立显卡拥有独立显存,而集成显卡通常是没有的,需要占用部分主内存来达到缓存的目的
集成显卡: 是集成在主板上的,与主处理器共享系统内存。 一般会在很多轻便薄型的…
编译 CUDA加速的 OpenCV-4.8.0 版本
文章目录 前言一、编译环境二、前期准备三、CMake编译四、VS编译OpenCV.sln五、问题 前言
由于项目需要用上CUDA加速的OpenCV,编译时也踩了不少坑,所以这里记录一下。 一、编译环境
我的编译环境是: Win10 RTX4050 CUDA-12.0 CUDNN 8.9.…
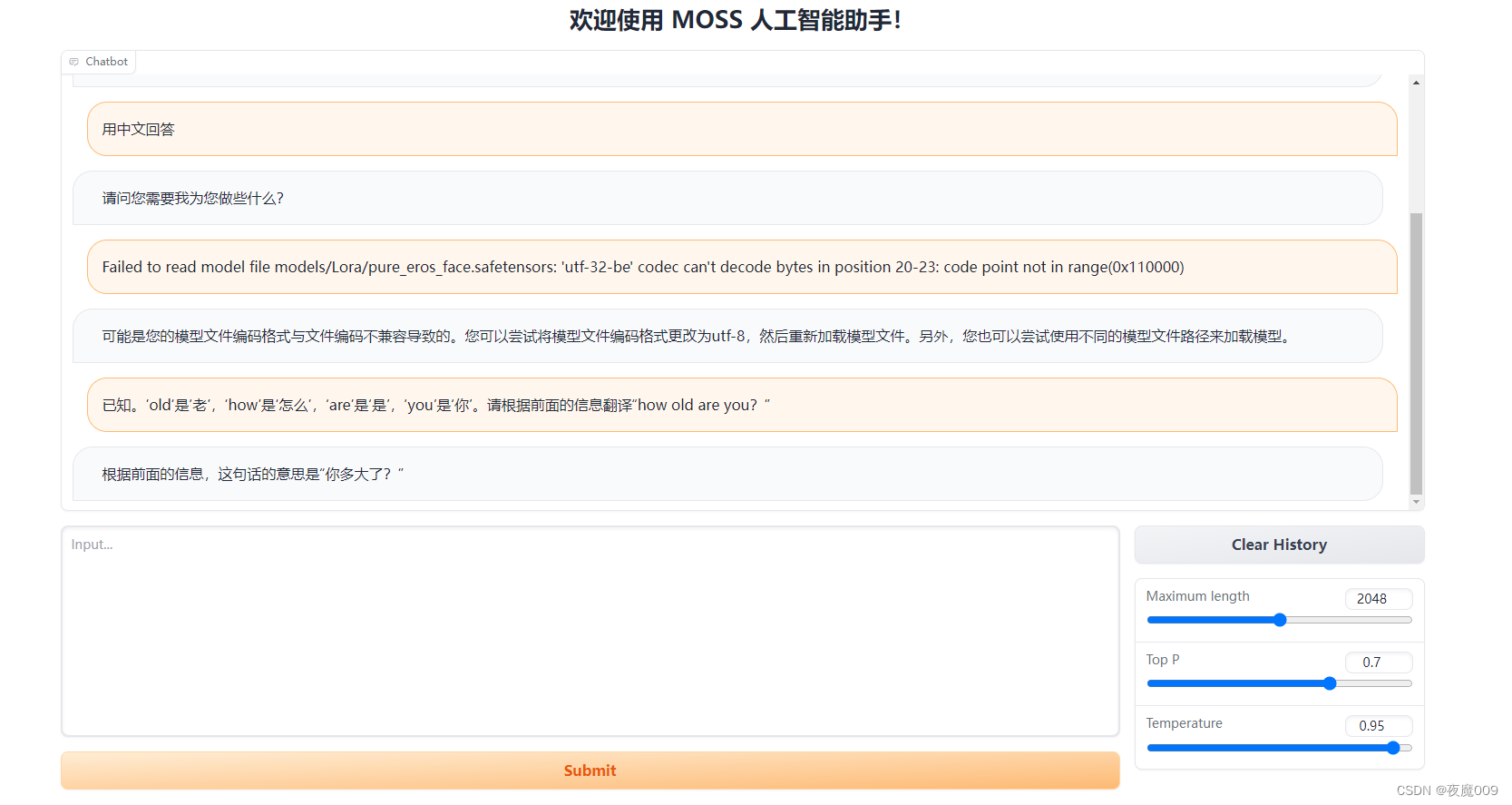
基于趋动云部署复旦大学MOSS大模型
首先新建项目:
MOSS部署项目,然后选择镜像,直接用官方的镜像就可以。
之后选择数据集:
公开数据集中,MOSS_复旦大学_superx 这个数据集就是了,大小31G多 完成选择后: 点击创建,…

极智开发 | CUDA Memory内存模型
欢迎关注我的公众号 [极智视界],获取我的更多经验分享
大家好,我是极智视界,本文分享一下 CUDA Memory内存模型。 邀您加入我的知识星球「极智视界」,星球内有超多好玩的项目实战源码和资源下载,链接:https://t.zsxq.com/0aiNxERDq 熟悉和了解 CUDA Memory 内存模型对于…

real time rendering 4th-Chapter03-GPU
Data Parallel Architectures if 问题
如果在一个warp中所有的线程都按照同样的路径运行,那么效率不会有问题如果在一个warp中有的线程执行路径A,有的执行路径B那么,就会出现问题。有的线程就需要等待别的线程。比如:有的线程在执…
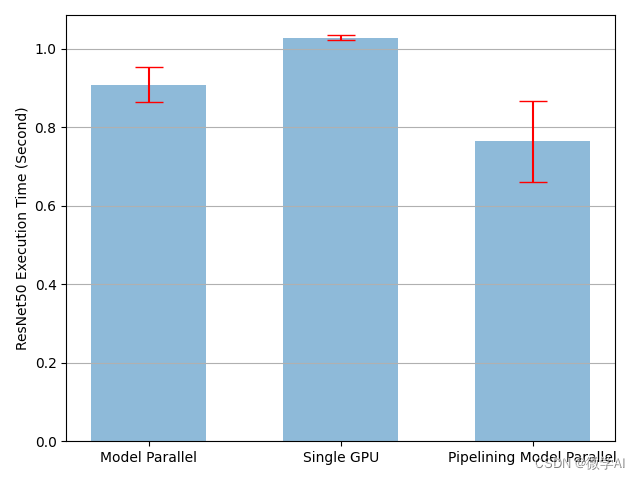
深度学习技巧应用33-零门槛实现模型在多个GPU的分布式流水线训练的应用技巧
大家好,我是微学AI,今天给大家介绍一下深度学习技巧应用33零门槛实现模型在多个GPU的分布式流水线训练的应用技巧,本文将帮助大家零门槛的实现模型在多个GPU的并行训练,如果你手头上没有GPU资源,根据本文的介绍也可实现…
![[Orin Nx] 如何跑满GPU和CPU,观察温度和散热性能?](https://img-blog.csdnimg.cn/ea96323b6bdb4d3bb2a5bacb6385230b.png)
[Orin Nx] 如何跑满GPU和CPU,观察温度和散热性能?
1、环境说明
硬件: Nvidia Orin NX 16GB
软件:Jetson Linux R35.3.1 2、工具安装部署
GPU的压力测试主要使用工具:
https://github.com/anseeto/jetson-gpu-burn
CPU的压力测试主要使用工具 stress
注意安装 jetson-gpu-burn需要在 /etc/apt/sourc…
LLM - 训练与推理过程中的 GPU 算力评估
目录
一.引言
二.FLOPs 和 TFLOPs
◆ FLOPs [Floating point Opearation Per Second]
◆ TFLOPs [Tera Floating point Opearation Per Second]
三.训练阶段的 GPU 消耗
◆ 影响训练的因素
◆ GPT-3 训练统计
◆ 自定义训练 GPU 评估
四.推理阶段的 GPU 消耗
◆ 影响…
CUDA示例学习:HelloCUDA
//hellocuda.cu
#include <iostream>
#include "stdio.h"__global__ void kernel(void){printf("hello, cvudakernel\n");}int main(void){kernel<<<1,5>>>();cudaDeviceReset();return 0 ;
}在命令行执行
$nvcc hellocuda.cu -o…

深度学习在人体动作识别领域的应用:开源工具、数据集资源及趋动云GPU算力不可或缺
人体动作识别检测是一种通过使用计算机视觉和深度学习技术,对人体姿态和动作进行实时监测和分析的技术。该技术旨在从图像或视频中提取有关人体姿态、动作和行为的信息,以便更深入地识别和理解人的活动。
人体动作识别检测的基本步骤包括: 数…
CUDA各版本网址、CUDNN各版本网、以及对应关系
CUDA网址:CUDACUDNN网址:CUDNN对应关系网址:官网对应关系 (在最下面)
PVRTexTool使用
下载
imaginationtech官网下载PVRTexTool安装
使用
查看帮助
./PVRTexToolCLI.exe help使用CLI向下2次幂宽高改变png图片的尺寸
.\PVRTexToolCLI.exe -pot - -f r8g8b8a8 -i input.png -d output.png -noout使用CLI向下2次幂宽高改变png图片canvas的尺寸
.\PVRTexToolCLI…
CPU和GPU交互的初理解
GPU和CPU交互的那部分可以看成一个全局表GPU_table, 这个表里的一级下表为ARRAY_BUFFER,ELEMENT_ARRAY_BUFFER等各种buffer 单看这个一级表可以把他们理解为各种缓冲区 这个表里的二级下表为各种glID缓冲对象 这个表里的三级下表为实实在在的data
特别注意…

使用 WSLg 的 vGPU 硬件加速新特性创建重度混合生产环境
使用 WSLg 的 vGPU 硬件加速新特性创建重度混合生产环境
本文首发于:白泽阁-使用 WSLg 的 vGPU 硬件加速新特性创建重度混合生产环境
一、不同版本的WSL
Windows Subsystem for Linux(简称WSL)是一个在 Windows 10\11 上能够运行原生Linux…
极智开发 | 你真的了解GPU nvidia-smi指令吗
欢迎关注我的公众号 [极智视界],获取我的更多经验分享
大家好,我是极智视界,本文分享一下 你真的了解GPU nvidia-smi指令吗。 邀您加入我的知识星球「极智视界」,星球内有超多好玩的项目实战源码和资源下载,链接:https://t.zsxq.com/0aiNxERDq 对于 GPU 的这个指令,大家…
推荐算法再次踩坑记录
去年搞通了EasyRec这个玩意,没想到今年还要用推荐方面的东西,行吧,再来一次,再次踩坑试试。1、EasyRec训练测试数据下载:git clone后,进入EasyRec,然后执行:bash scripts/init.sh 将…
UWA报告使用小技巧,你get了吗?(第四弹)
UWA使用技巧小视频合辑继续更新啦~~
之前的UWA报告使用小技巧第一弹、第二弹和第三弹推出后,不少开发者和我们反馈原来报告中暗藏这么多玄机!因此,贴心的小编又为大家准备了5条真人真机测试和GOT Online报告使用小技巧…
OpenCVSharp使用GPU和Cuda
背景:在C#项目实践中,对与图像处理采用opencv优选的方案有两种,EMGU.CV和OpenCVSharp。
以下是两个的比较:
Opencv方案许可证速度支持易用性OpenCVSharp许可证是阿帕奇2.0可以随意用快CPU上手简单EMGU.CV许可证商用时需要随软件…
GPU深度学习性能的三驾马车:Tensor Core、内存带宽与内存层次结构
编者按:近年来,深度学习应用日益广泛,其需求也在快速增长。那么,我们该如何选择合适的 GPU 来获得最优的训练和推理性能呢? 今天,我们为大家带来的这篇文章,作者的核心观点是:Tensor…

浅谈AI算力优化技术
一、AI算力的主要构成
在人工智能三要素中,无论是数据还是算法,都离不开算力的支撑。根据IDC报告,过去,用户对于人工智能的感知更多停留在数据层和应用层,随着非结构化数据的激增和算法框架的日益复杂,算力…
centos搭建paddle环境(GPU)
GPU驱动安装
Nvidia Driver 安装
lsmod | grep nouveau
yum list | grep kernel-devel虚拟环境搭建
配置镜像
pip config set global.index-url https://pypi.tuna.tsinghua.edu.cn/simple
安装miniconda
anaconda是包含一些常用包的版本(这里的常用不代表你常…
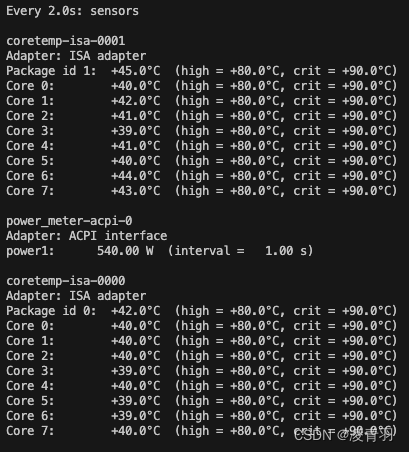
linux实时显示CPU温度
使用 sensors 命令 服务器跑深度学习,自动关机,4张GPU显卡温度80~90度,但是显卡温度高不会导致电脑重启,电脑重启多半是线程多(Pytorch调用CPU较多,导致CPU计算任务重;)&…

如何在docker中访问电脑上的GPU?如何在docker中使用GPU进行模型训练或者加载调用?
如何在docker中访问电脑上的GPU?如何在docker中使用GPU进行模型训练或者加载调用? 其实使用非常简单,只是一行命令的事,最主要的事配置好驱动和权限。
docker run -it --rm --gpus all ycj520/centos:1.0.0 nvidia-smi先看看 st…

高通芯片GPU是否有类似于HSR功能
1)高通芯片GPU是否有类似于HSR的功能 2)UGUI上的RT动图会不会导致UI更新 3)UI经常迭代外观,如何尽量少改代码 4)开发过程中该使用AssetBundle包模式,还是模拟模式? 这是第279篇UWA技术知识分享…

聊聊GPU利用率那些事
引言
众所周知,GPU本身的计算能力是越来越强大,特别是新一代的NVIDIA AMPERE架构发布之后,又一次刷新了大家对AI算力的认知。目前,确实有不少大规模分布式训练对更大算力的渴求是极其强烈的,比如语音、自然语言处理等…

CUDA虚拟内存管理
CUDA中的虚拟内存管理 文章目录CUDA中的虚拟内存管理1. Introduction2. Query for support3. Allocating Physical Memory3.1. Shareable Memory Allocations3.2. Memory Type3.2.1. Compressible Memory4. Reserving a Virtual Address Range5. Virtual Aliasing Support6. Ma…

Roofline Model Toolkit: A Practical Tool for Architectural and Program Analysis
Roofline Model Toolkit: A Practical Tool for Architectural and Program Analysis 描述了 Roofline Toolkit 的原型架构表征引擎。该引擎由一组使用消息传递接口(Message Passing Interface,MPI )以及用于表示线程级并行性的 OpenMP 实现的…
CUDA和TensorRT入门
CUDA
官方教程:CUDA C Programming Guide (nvidia.com)
一、基础知识
首先看一下显卡、GPU、和CUDA的关系介绍:
显卡、GPU和CUDA简介_吴一奇的博客-CSDN博客
延迟:一条指令返回的时间间隔;
吞吐量:单位时间内处理…

nvidia-smi nvcc -V 及 CUDA、cuDNN 安装
nvidia-smi nvcc -V 及 CUDA、cuDNN 安装 1. 问题缘由2. 分析3. CUDA Driver API 安装3.1 Software & Updates3.2 官网下载 4. CUDA Runtime API 安装5. 安装 cuDNN5.1 cuDNN下载 6. 一点点小注意事项 1. 问题缘由
之前查找 CUDA 版本时都是直接使用的 nvidia-smi 指令&am…
GPU安装指南:英伟达H800加速卡常见软件包安装命令
Latest commit
Fermi †Kepler †Maxwell ‡PascalVoltaTuringAmpereAda (Lovelace)Hoppersm_20sm_30sm_50sm_60sm_70sm_75sm_80sm_89sm_90sm_35sm_52sm_61sm_72(Xavier)sm_86sm_90a (Thor)sm_37sm_53sm_62sm_87 (Orin)
† Fermi and Kepler are deprecated from CUDA 9 and …

中国有那些公司需要HPC(高性能计算)的程序员?
不看不知道,一看吓一跳。HPC早就不是之前那样只存在于研究机关的角色了。尤其是2023年以来,中国有许多公司和研究机构需要高性能计算(HPC)的程序员,特别是在领域如科学研究、工程模拟、天气预报、金融建模、人工智能等…
趋动科技猎户座OrionX AI加速器资源池化软件——产品介绍
随着AI技术的快速发展,越来越多企业开始将AI技术应用到自身业务之中。因此,对AI算力的需求在近几年迅猛增长。其中,云端AI算力自2012年到现在增长了超过三十万倍,在可预见的将来依然会保持这个增速。目前,云端AI算力主…
Win7+CUDA8.0+VS2015+Theano0.8配置GPU加速环境
今天感觉至少做成了一件事,心情不错!
Nvidia官网给出的兼容性情况: 大致来说: Theano0.8的安装通过Anaconda然后pip install theano,细节参照Theano的官方文档Installation of Theano on Windows ,只要能…

智能电动汽车时代开启,漫谈车载算力发展
目录
引言
算力和芯片的关系
车载芯片有哪些
自动驾驶芯片和传统汽车芯片区别
为什么自动驾驶芯片需要这么高的算力
自动驾驶芯片发展现状
车载算力未来:算力是自动驾驶的前提 引言
无论是从2020年开始持续到今天的汽车缺芯问题,还是特斯拉在目…

WIN10+RTX3090显卡下CUDA11.1、cudnn11.1安装
WIN10RTX3090显卡下CUDA11.1、cudnn11.1安装 (1)Visual Studio 2017 Community(必须安装,Cuda是与其结合使用的) 安装好了“应用于功能”里面出现如下: 注:其实,起作用的就是红色框…
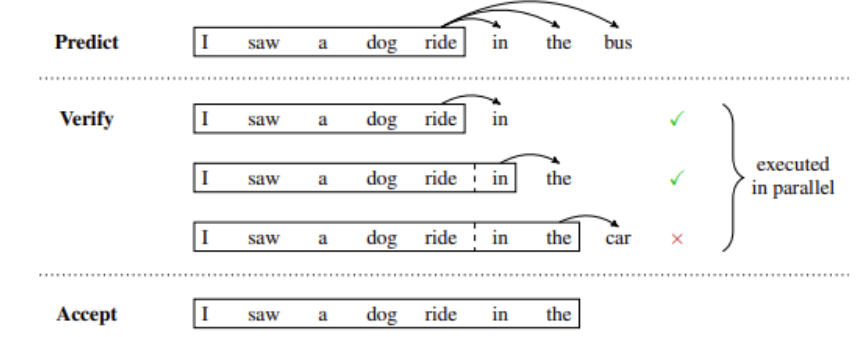
掌握大语言模型技术: 推理优化
掌握大语言模型技术_推理优化 堆叠 Transformer 层来创建大型模型可以带来更好的准确性、少样本学习能力,甚至在各种语言任务上具有接近人类的涌现能力。 这些基础模型的训练成本很高,并且在推理过程中可能会占用大量内存和计算资源(经常性成…

空闲 GPU 检测脚本
深度学习的任务往往需要花费很多训练时间,有的时候训练可能在深夜结束,人不在电脑前无法第一时间知道任务结束情况,GPU 只能空闲在那里而无法执行下一个训练任务。
为了提高效率我们可以写一个脚本检测 GPU 使用情况。
# author: Anthony
…

GPU 命令行释放内存
我们在使用tensorflowpycharm 写程序的时候, 有时候会在控制台终止掉正在运行的程序,但是有时候程序已经结束了,nvidia-smi也看到没有程序了,但是GPU的内存并没有释放,那么怎么解决该问题呢&am…
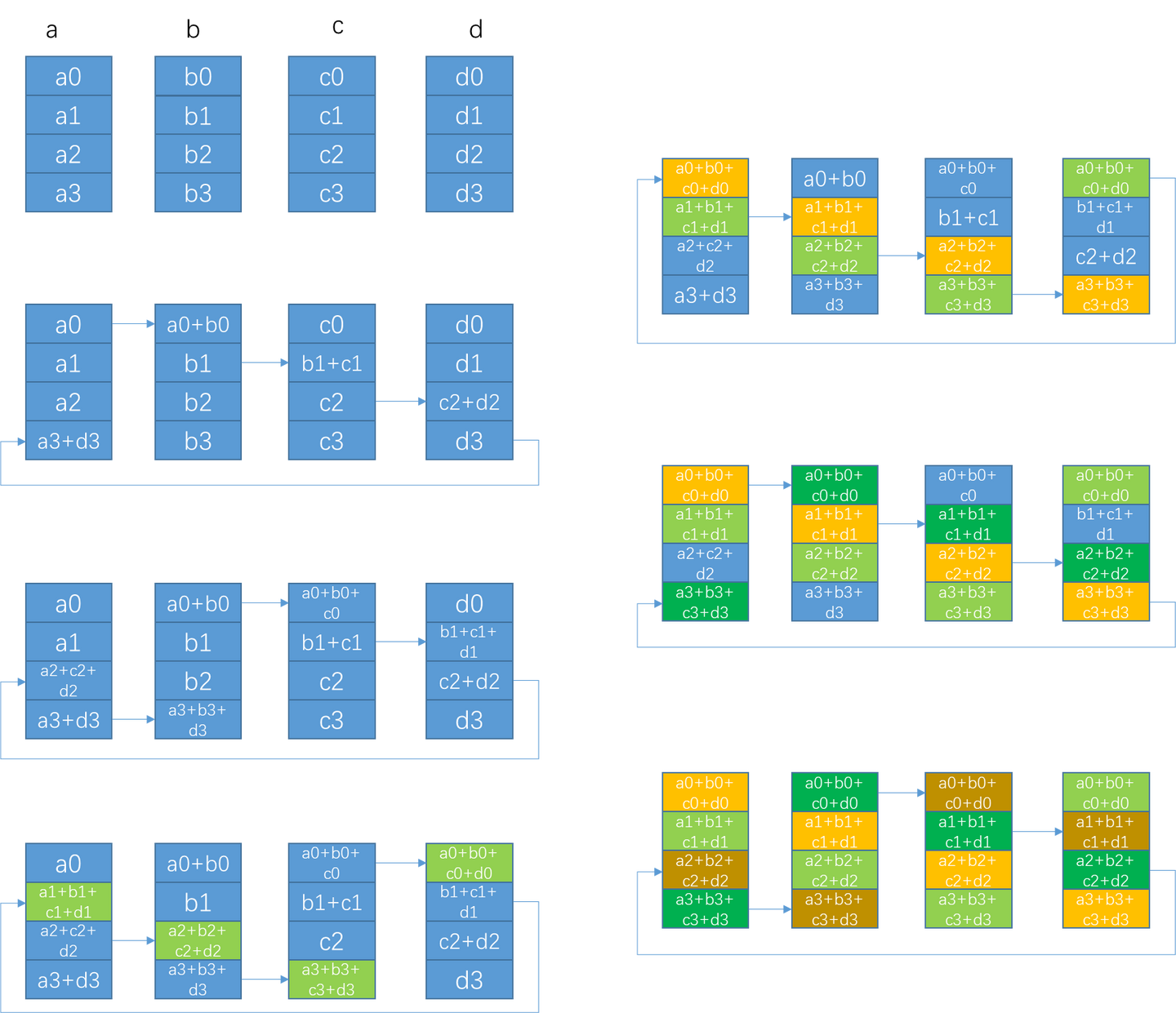
NVIDIA NCCL 源码学习(十一)- ring allreduce
之前的章节里我们看到了nccl send/recv通信的过程,本节我们以ring allreduce为例看下集合通信的过程。整体执行流程和send/recv很像,所以对于相似的流程只做简单介绍,主要介绍ring allreduce自己特有内容。
单机
搜索ring
在nccl初始化的过…
【教程】PyTorch Timer计时器
转载请注明出处:小锋学长生活大爆炸[xfxuezhang.cn] OpenCV的Timer计时器可以看这篇:Python Timer和TimerFPS计时工具类 Timer作用说明:统计某一段代码的运行耗时。
直接上代码,开箱即用。
import time
import torch
import os
…

下一代AI算力池化云长啥样?
10月24日,全球AI算力池化技术领导者趋动科技在“2022 长沙中国1024 程序员节”上正式发布业内首个AI算力池化云服务——趋动云VirtAI Cloud,面向所有AI相关企业、科研院所和个人开发者,提供像“用水用电”一样便宜好用的AI算力基础架构服务。…

CES2022国际消费类电子产品展览会,英特尔12代酷睿i5移动处理器性能曝光:单核超酷睿i7-11800H
intel 英特尔
根据 CES 2022 官网的消息,英特尔将于拉斯维加斯时间 1 月 4 日上午 10 点举行媒体发布会,也就是北京时间 1 月 5 日凌晨 2 点。
英特尔预计将会在CES 2022期间发布笔记本CPU,其中就包括12代移动处理器,可以说是明…
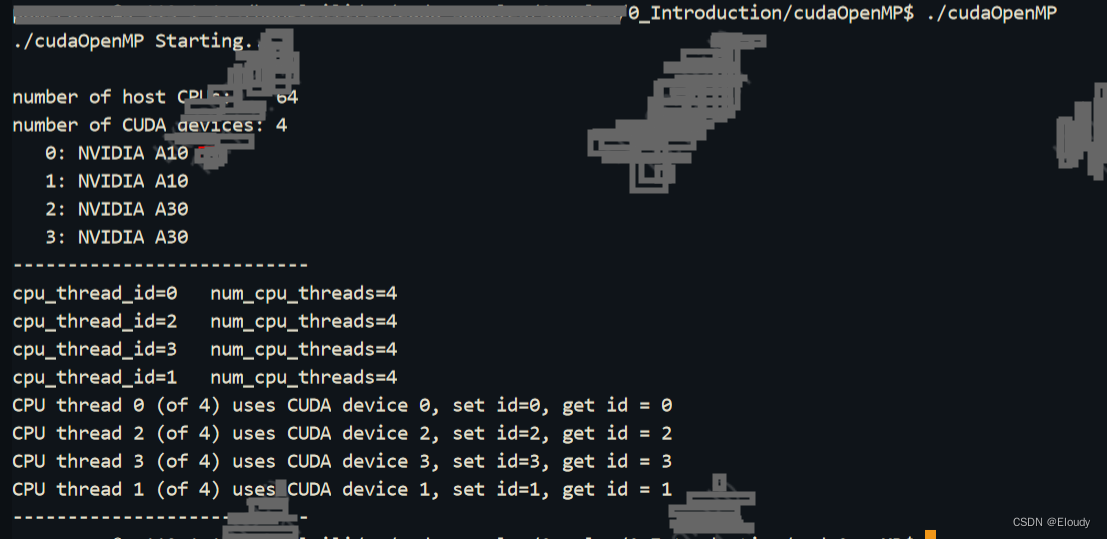
cuda lib 线程安全的要义
1, 概述 cuda lib 线程安全的几个多线程的情景:
单卡多线程;
多卡多线程-每卡单线程;
多卡多线程-每卡多线程; 需要考虑的问题: 每个 cublasHandle_t 只能有一个stream么? 每个cusolverHandle_t 只能有一…
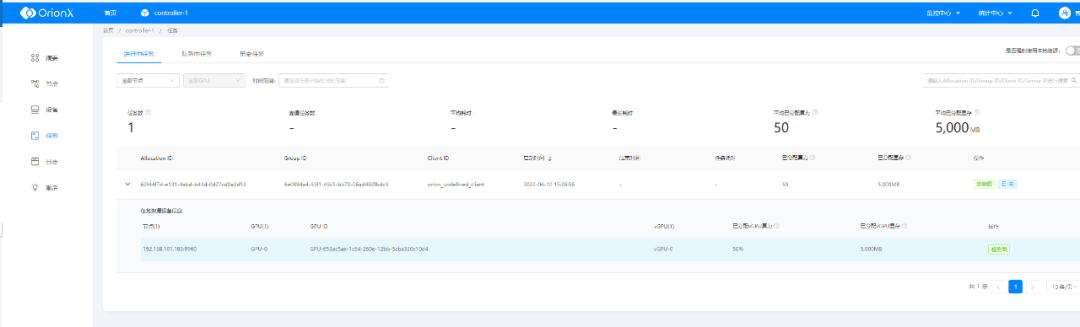
OrionX vGPU研发测试场景下最佳实践之Jupyter模式
在上周的文章中,我们讲述了OrionX vGPU研发测试场景下最佳实践之SSH模式,今天,让我们走进 Jupyter模式下的最佳实践。 Jupyter模式:Jupyter是最近几年算法人员使用比较多的一种工具,很多企业已经将其改造集成开发工具&…
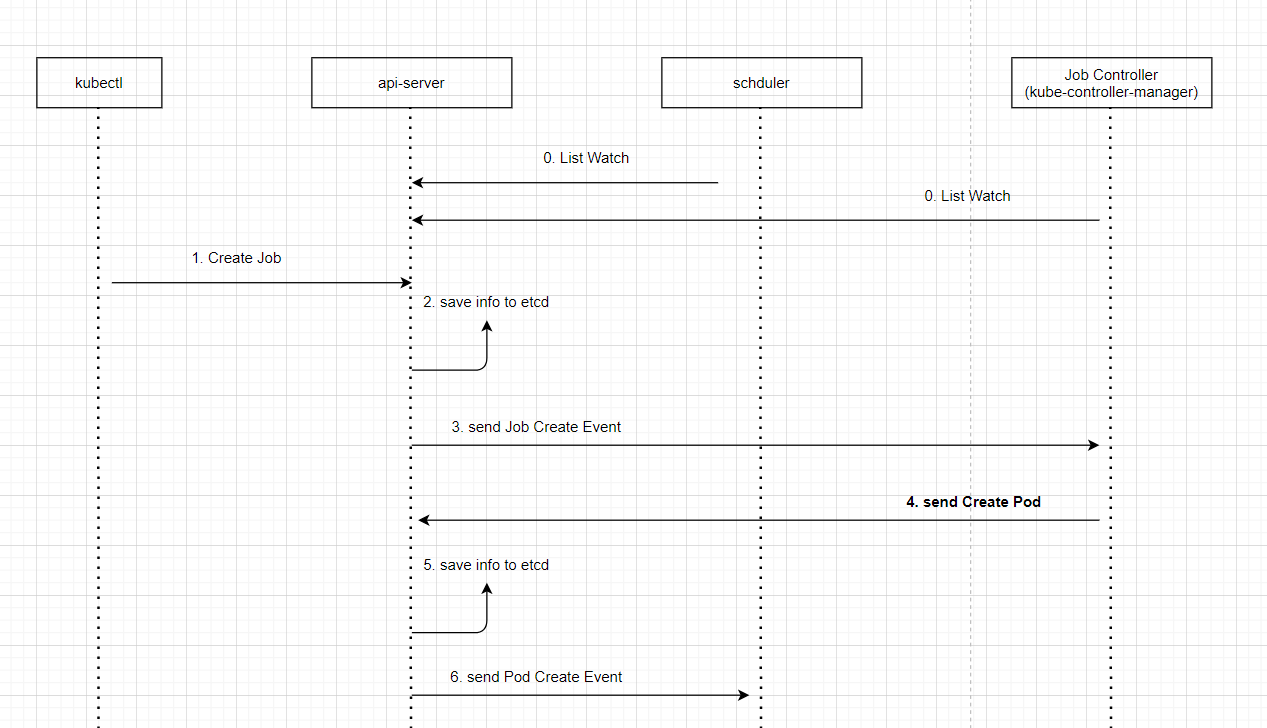
k8s集群部分使用gpu资源的pod出现UnexpectedAdmissionError问题
记录一次排查UnexpectedAdmissionError问题的过程
1. 问题
环境
3master节点N个GPU节点
kubelet版本:v1.19.4
kubernetes版本:v1.19.4
生产环境K8S集群,莫名其妙的出现大量UnexpectedAdmissionError状态的Pod,导致部分任务执…

【GPU】NVIDIA驱动安装
我在网上一共看到两种NVIDIA驱动的安装方法: ppa源安装,参考链接:最全面解析 Ubuntu 16.04 安装nvidia驱动 以及各种错误 手动run文件安装,参考链接:Ubuntu16.04安装Nvidia显卡驱动(cuda)以r…

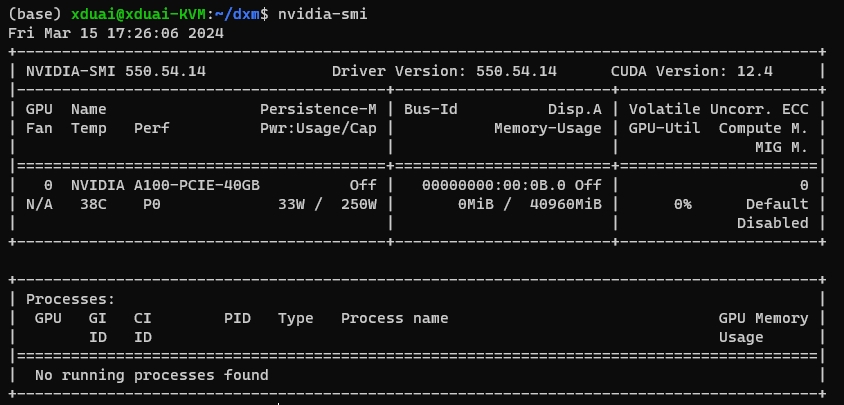
nvidia-smi 命令详解
nvidia-smi 命令详解 1. nvidia-smi 面板解析2. 显存与GPU的区别 Reference: nvidia-smi命令详解
相关文章:
nvidia-smi nvcc -V 及 CUDA、cuDNN 安装
nvidia-smi(NVIDIA System Management Interface) 是一种命令行实用程序,用于监控和管理 NVIDIA G…

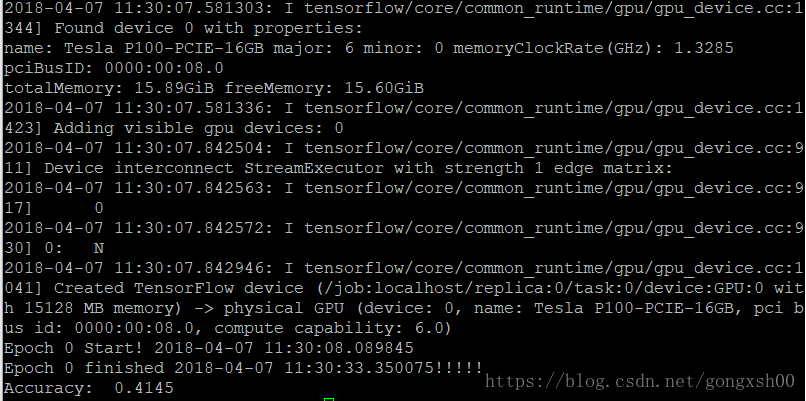
使用GPU加速TensorFlow机器学习
在Thinkpad X260上运行一个CNN图像分类的样例程序时,发现速度特别慢,迭代一轮要将近5分钟,那么迭代200轮需要1000分钟,16个小时!在看到TensorFlow相关的书籍时,总是提到GPU加速,对于这样的问题&…
【已解决】torch.cuda.is_available()提示The NVIDIA driver on your system is too old (found version 10000)
最直接的表现是安装完pytorch,训练GPU计算单元使用率是0。强制device,报错。遂查看torch.cuda.is_available()提示The NVIDIA driver on your system is too old (found version 10000)。 原因是我的cuda 10.0 我安装 pytorch 1.7.1的时候 安装的是
con…
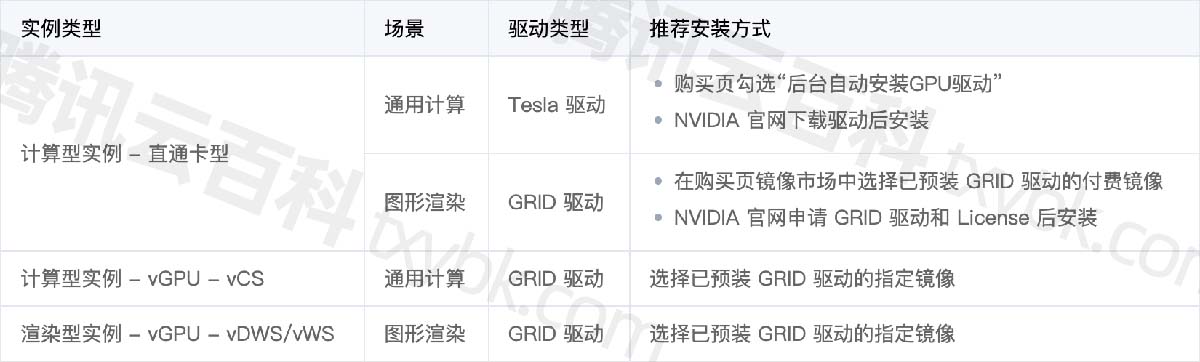
腾讯云GPU服务器介绍_GPU实例规格价格_AI_深度学习
腾讯云GPU服务器是提供GPU算力的弹性计算服务,腾讯云GPU服务器具有超强的并行计算能力,可用于深度学习训练、科学计算、图形图像处理、视频编解码等场景,腾讯云百科txybk.com整理腾讯云GPU服务器租用价格表、GPU实例优势、GPU解决方案、GPU软…

NVIDIA 、 显卡、显卡组成、GPU 介绍、GPU与CPU。
这里是我写的一个 英伟达显卡学习的 导航目录,欢迎大家点击观看,希望可以给您带来好处:
学习导航目录: 关于 NVIDIA: 1993年,黄仁勋、与Sun公司的Chris Malachowsky和Curtis Priem 共同创立了英伟达&#…
CUDA并行计算基础知识
1、相关缩写术语 显卡:GPU 显卡驱动:驱动软件 GPU架构: 硬件的设计方式,例如是否有L1 or L2缓存 CUDA: 一种编程语言像C++, Python等,只不过它是专门用来操控GPU的 cudnn: 一个专门为深度学习计算设计的软件库,里面提供了很多专门的计算函数 CUDAToolkit:所谓的装cuda首先…

CPU与GPU的区别(转载知乎)
首先需要解释CPU和GPU这两个缩写分别代表什么。CPU即中央处理器,GPU即图形处理器。 其次,要解释两者的区别,要先明白两者的相同之处:两者都有总线和外界联系,有自己的缓存体系,以及数字和逻辑运算单元。一句…

第 12 代智能英特尔酷睿移动式处理器
第 12 代英特尔 酷睿™ 移动处理器采用全新性能混合架构,为笔记本电脑重新定义多核架构。基于全新的英特尔 7 制造工艺,这一设计突破汇集了两种专业型内核,提供了革命性的性能和相应速度。最新的平台技术,如 DDR5 内存支持、雷电技…
【FPGA原型验证】附录基础知识:FPGA/CPLD基本结构与实现原理
聚焦Xilinx ISE
介绍Xilinx公司及其产品的基本情况,并在此基础上描述了CPLD和FPGA的内部结构及基本原理。
1.1 Xilinx公司及其产品介绍
总部设在加利福尼亚圣何塞市(San Jose)的Xilinx是全球领先的可编程逻辑解决方案的供应商,图1-1为公司标志。
Xilinx公司的业务是研发…
Theano 配置GPU出错:g++: error trying to exec 'cc1plus': No such file or directory
笔者近日尝试使用pylearn2,想要给theano配置GPU加速,然而在import theano时出现“g: error trying to exec ‘cc1plus’: execvp: No such file or directory错误”,最终发现是gcc与g版本不兼容造成的错误。 问题描述: 安装CUDA&a…

Roofline-on-NVIDIA-GPUs代码分析
Roofline 代码现状:
CS Roofline Toolkit 为 Roofline Model Toolkit: A Practical Tool for Architectural and Program Analysis 的实现,uo-cdux/ert-mirror 为 github 上的一个镜像;cyanguwa/nersc-roofline 为 Hierarchical Roofline An…

Linux conda中Tensorflow GPU安装配置全面梳理(包含cuda、cudnn)
CPU VS GPU CPU: 中央处理单元。由数百万个晶体管组成,可以有多个处理内核,执行计算机和操作系统所需的命令和流程。GPU: 图形处理单元。由许多更小、更专业的内核组成的处理器。 在多个内核之间划分并执行一项处理任务时,通过协同工作&#…
深度学习硬件:CPU、GPU、FPGA、ASIC
人工智能包括三个要素:算法,计算和数据。人工智能算法目前最主流的是深度学习。计算所对应的硬件平台有:CPU、GPU、FPGA、ASIC。由于移动互联网的到来,用户每天产生大量的数据被入口应用收集:搜索、通讯。我们的QQ、微…
CPU与GPU区别 通俗易懂
为什么二者会有如此的不同呢?首先要从CPU和GPU的区别说起。 CPU和GPU之所以大不相同,是由于其设计目标的不同,它们分别针对了两种不同的应用场景。CPU需要很强的通用性来处理各种不同的数据类型,同时又要逻辑判断又会引入大量的分…
【GPU】Cuda和CuDNN安装
CUDA Toolkit and Compatible Driver Versions
NVIDIA CUDA Installation Guide for Linux
Download CUDNN cuda 版本 cat /usr/local/cuda/version.txt
cudnn 版本 cat /usr/local/cuda/include/cudnn.h | grep CUDNN_MAJOR -A 2 参考链接:Ubuntu 16.04 上安装…
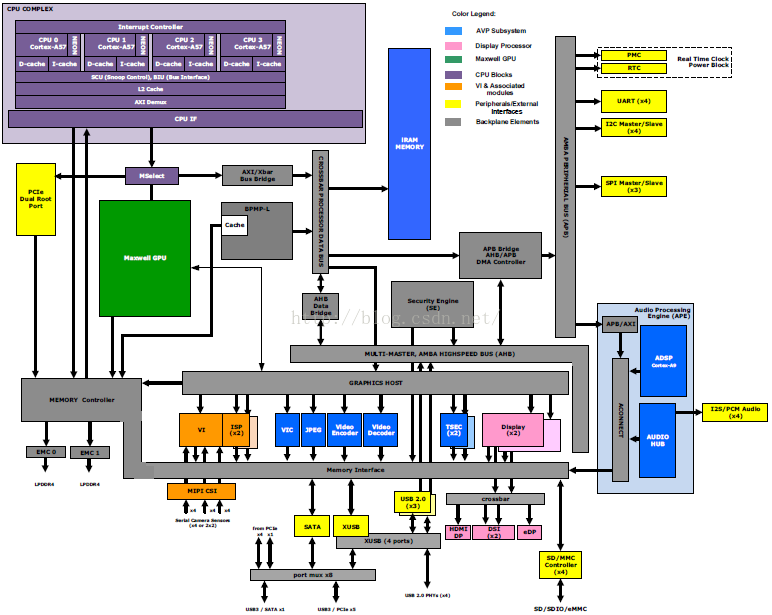
NVIDIA Jetson TX1(2)
1.0 模块概述
Jetson TX1 SoM集成了下面器件和接口:
l NVIDIA Tegra X1 SoC
l LPDDR4内存
l eMMC 5.1存储器件
l 802.11 ac 2x2 WiFi
l Gigabit以太网
l PMIC
l 导热板(TTP)
l 400脚的板与板之间连接器,…

【Tensorflow】超详细!!!手把手教学安装tensorflow,从anaconda到tensorflow-gpu安装全过程!
目录1.安装anaconda1.1更换conda镜像源1.2安装一个tensorflow环境2.安装tensorflow-gpu2.1查看安装什么版本的tensorflow-gpu3.安装cuda和cudnn3.1下载cuda3.2安装cuda3.3下载cudnn3.4将对应的cudnn文件放入cuda中3.5添加环境变量4.pycharm导入刚刚安装的tensorflow环境1.安装a…

(含代码)利用NVIDIA Triton加速Stable Diffusion XL推理速度
在 NVIDIA AI 推理平台上使用 Stable Diffusion XL 生成令人惊叹的图像 扩散模型正在改变跨行业的创意工作流程。 这些模型通过去噪扩散技术迭代地将随机噪声塑造成人工智能生成的艺术,从而基于简单的文本或图像输入生成令人惊叹的图像。 这可以应用于许多企业用例&…
极智芯 | 解读近存计算AI芯势力Groq LPU
欢迎关注我的公众号「极智视界」,获取我的更多技术分享
大家好,我是极智视界,本文分享一下 解读近存计算AI芯势力Groq LPU。 邀您加入我的知识星球「极智视界」,星球内有超多好玩的项目实战源码和资源下载,链接:https://t.zsxq.com/0aiNxERDq 当然,标题用了 "一语…
解决ubuntu 22.04新内核6.5.0-15无法编译NVIDIA显卡驱动
这里的新内核应该包括6.5.*系列的 文章目录 遇到的问题: 遇到的问题:
今天我在安装NVIDIA显卡驱动发现了一个问题,主要日志如下所示:
make[3]: *** [scripts/Makefile.build:251: /tmp/selfgz1310041/NVIDIA-Linux-x86_64-550.5…
Docker【部署 05】docker使用tensorflow-gpu安装及调用GPU踩坑记录
tensorflow-gpu安装及调用GPU踩坑记录 1.安装tensorflow-gpu2.Docker使用GPU2.1 Could not find cuda drivers2.2 was unable to find libcuda.so DSO2.3 Could not find TensorRT&&Cannot dlopen some GPU libraries2.4 Could not create cudnn handle: CUDNN_STATUS_…
LLM大语言模型(一):ChatGLM3-6B本地部署
目录 前言
本机环境
ChatGLM3代码库下载
模型文件下载
修改为从本地模型文件启动
启动模型网页版对话demo
超参数设置
GPU资源使用情况 (网页对话非常流畅) 前言
LLM大语言模型工程化,在本地搭建一套开源的LLM,方便后续的…
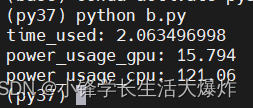
【教程】Python实时检测CPU和GPU的功耗
目录
前言
GPU功耗检测方法
CPU功耗检测方法
sudo的困扰与解决
完整功耗分析示例代码 转载请注明出处:小锋学长生活大爆炸[xfxuezhang.cn] 前言 相关一些检测工具挺多的,比如powertop、powerstat、s-tui等。但如何通过代码的方式来实时检测…
使用CUDA计算GPU的理论显存带宽
文章目录 一、显存带宽和理论显存带宽1. 显存带宽2. 理论显存带宽1)计算公式2)举例 二、利用CUDA计算理论显存带宽 一、显存带宽和理论显存带宽
1. 显存带宽
显存带宽是指显存和GPU计算单元之间的数据传输速率。
显存带宽越大,意味着数据传…

CUDA中的数学方法
CUDA中的数学方法 文章目录CUDA中的数学方法1. Standard FunctionsSingle-Precision Floating-Point FunctionsDouble-Precision Floating-Point Functions2. Intrinsic FunctionsSingle-Precision Floating-Point FunctionsDouble-Precision Floating-Point Functions参考手册…
Python大型数据集(GPU)可视化和Pillow解释性视觉推理及材料粒子凝聚
🎯要点
Python图像处理Pillow库:🎯打开图像、保存图像、保存期间的压缩方式、读取方法、创建缩略图、创建图像查看器。🎯获取 RGB 值,从图像中获取颜色,更改像素颜色,转换为黑…
利用Lora调整和部署 LLM
使用 NVIDIA TensorRT-LLM 调整和部署 LoRA LLM 大型语言模型 (LLM) 能够从大量文本中学习并为各种任务和领域生成流畅且连贯的文本,从而彻底改变了自然语言处理 (NLP)。 然而,定制LLM是一项具有挑战性的任务,通常需要完整的培训过程…
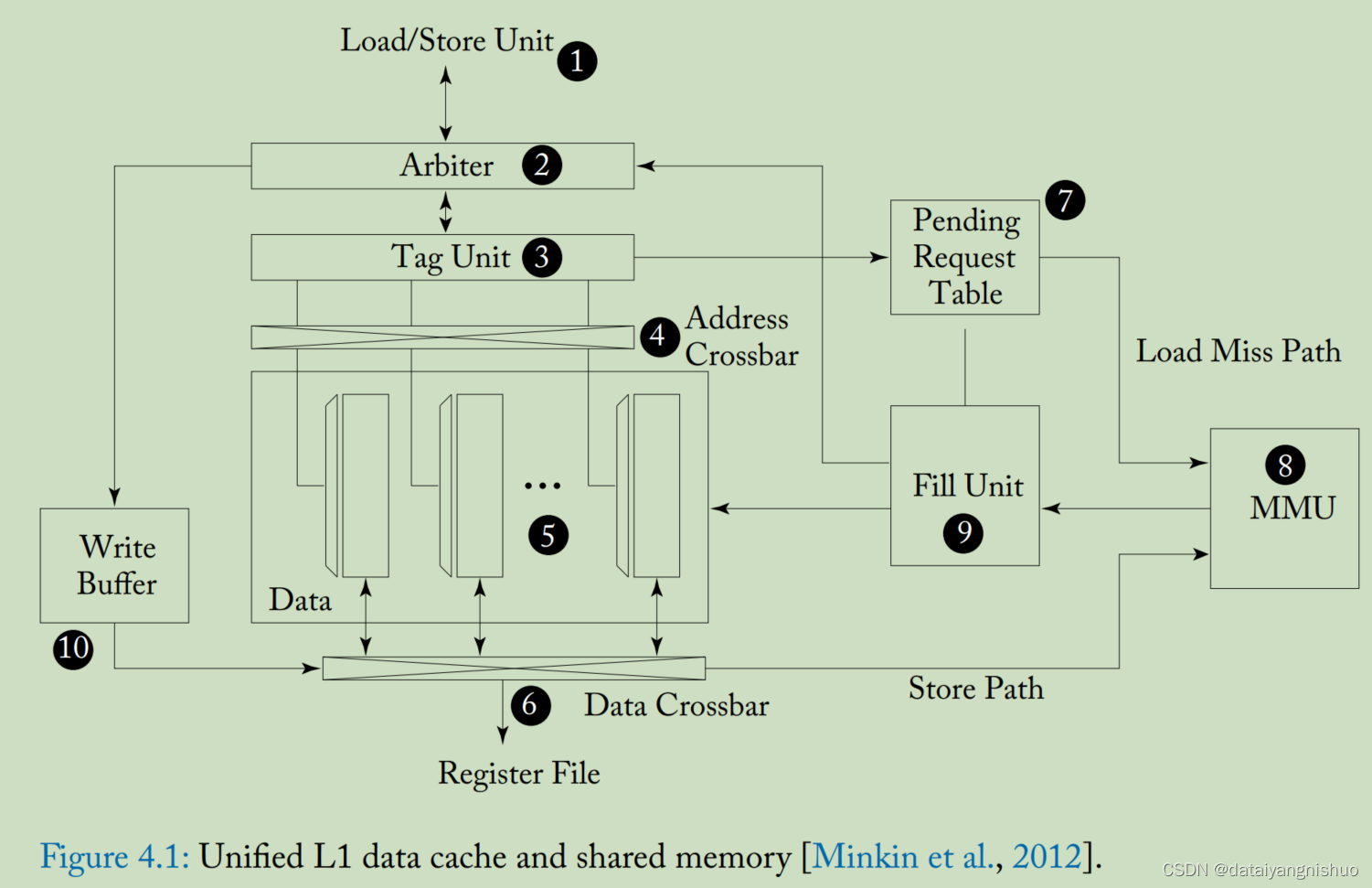
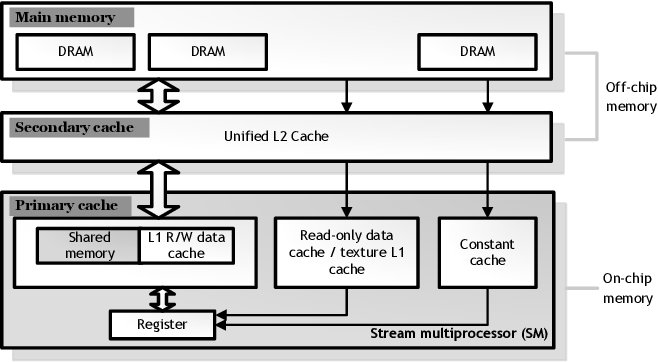
4.1 一级存储结构
本节介绍 GPU 上的一级缓存结构,重点介绍统一的 L1 数据缓存和暂存器“共享内存”,以及它们如何与计算核心交互。 我们还简要讨论了 L1 纹理缓存的典型微架构。 我们包括对纹理缓存的讨论,虽然它在 GPU 计算应用程序中的使用有限,…

GPU的算力超分和显存扩容探索
目录
云计算的资源超分超配
CPU的超分
内存的超分
存储的超配
GPU资源的超分超配探索
算力的超分
显存的扩容 云计算的资源超分超配
计算、存储、网络是云计算的基石,也是最宝贵的资源,如何进一步提高这些虚拟化之后资源的利用率就成为了控制成本…
pytorch使用多GPU进行训练
首先需要在代码开头注明所使用的GPU序号,比如:
import torch.nn as nn
import osos.environ["CUDA_VISIBLE_DEVICES"] 0,1对linux系统来说,可以使用
watch -n 0.1 nvidia-smi来查看服务器上GPU的状态与可用GPU序号。…

NVIDIA最新 Blackwell架构简介
NVIDIA Blackwell架构简介 在AI和大型语言模型(LLMs)迅速发展的领域中,追求实时性能和可扩展性至关重要。从医疗保健到汽车行业,组织正深入探索生成性AI和加速计算解决方案的领域。对生成性AI解决方案的需求激增,促使企…

linux ps 和 kill 以及如何调用某个单一的GPU进行运算
linux ps 和 kill 以及如何调用某个单一的GPU进行运算
作为一个linux小白,我开始了我的linux深度学习的旅程,这几天突击了一下莫凡的视频,真的是一个快速上手TensorFlow,keras和pytorch的教学视频,其中网址如下&#…

一、在GPU上执行运算
本文Demo
环境:
mac os 10.14.5
xcode 10.3
此系列文章源自官方案例,详情至 此处
专用名词虽有汉字翻译,但会保留原有英文形式名词。 概述
在此示例中,会学习在所有 Metal apps 中使用到的基本要素:
aÿ…

cuSPARSE官方程序示例
cuSPARSE Library
简介
这个文件演示了cuSPARSE通用API的用法
官方程序:后续会出解析(20230410)
cuSPARSE Generic APIs Documentation
cuSPARSE Samples
向量 - 向量 操作矩阵 - 向量 操作矩阵 - 矩阵操作转换Legacy APIs优化稀疏迭代…

Android开发者选项之GPU过度绘制
GPU过度绘制定义
如果你粉刷过一个房间或一所房子,就会知道给墙壁涂上颜色需要做大量的工作。假如你还要重新粉刷一次的话,第二次粉刷的颜色会覆盖住第一次的颜色,第一次的颜色就永远不可见了,等于你第一次粉刷做的大量工作就完全…

深度学习神经网络训练环境配置以及演示
🎬个人简介:一个全栈工程师的升级之路! 📋个人专栏:高性能(HPC)开发基础教程 🎀CSDN主页 发狂的小花 🌄人生秘诀:学习的本质就是极致重复! 目录
1 NVIDIA Dr…

DatenLord前沿技术分享 No.19
达坦科技专注于打造新一代开源跨云存储平台DatenLord,致力于解决多云架构、多数据中心场景下异构存储、数据统一管理需求等问题,以满足不同行业客户对海量数据跨云、跨数据中心高性能访问的需求。GPU编程可以大幅提升计算速度和效率,从而使得…
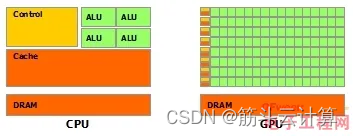
CPU vs. GPU :本质差异是?
他们的目的都是做并行计算的,但并行计算可分为时间上的并行和空间上的并行。所以我觉得本质差异是:
CPU 时间并行GPU 空间并行 这样就容易理解他们的工作方式:
对CPU来说,不同的核心可以执行不同的机器指令但GPU则不同ÿ…
普法安利一个调试debug小技巧
普法安利一个调试debug小技巧 引言 博客沉寂很久,肯定不是干坏事被抓吃公交粮食去了!而是最近忙着给OpenHarmony鸿蒙适配GPU渲染加速。尼玛,其中的各种坑啊,填了一个又一个,其中最最拖延了开发进度的事情就是给鸿蒙适配…

昨天Google发布了最新的开源模型Gemma,今天我来体验一下
前言
看看以前写的文章,业余搞人工智能还是很早之前的事情了,之前为了高工资,一直想从事人工智能相关的工作都没有实现。现在终于可以安静地系统地学习一下了。也是一边学习一边写博客记录吧。 昨天Google发布了最新的开源模型Gemma…

显卡基础知识及元器件原理分析
显卡应该算是是目前最为火热的研发方向了,其中的明星公司当属英伟达。 当地时间8月23日,英伟达发布截至7月30日的2024财年第二财季财报,营收和利润成倍增长,均超市场预期。
财报显示,第二财季英伟达营收为135.07 亿美…

为深度学习选择最好的GPU
在进行机器学习项目时,特别是在处理深度学习和神经网络时,最好使用GPU而不是CPU来处理,因为在神经网络方面,即使是一个非常基本的GPU也会胜过CPU。 但是你应该买哪种GPU呢?本文将总结需要考虑的相关因素,以便可以根据…
Python利用队列Queue实现多进程Process间通信
背景:
我在利用大模型进行推理的时候,一个机器上面有8张GPU卡,如何充分的利用这几张卡呢?最开始想到的是利用Python多线程方案,可代码实现之后发现虽然我在环境变量里面设置可以使用多张GPU卡,可程序依然只…
NVIDIA_A100_SXM2_40GB加速卡详细参数
记录了NVIDIA_A100_SXM2_40GB加速卡的详细参数 参考链接: https://www.xincanshu.com/gpu/NVIDIA_A100_SXM4_40_GB/canshu.html
主要参数
参数值描述核心频率1095 MHz核心 一秒内能够进行多少处理周期Turbo频率1410 MHz突发加速频率,类似于CPU睿频流处理单元6912 …
关于keras中使用CPU/GPU的配置(包含tensorboard使用)
参考:keras分批训练指定GPU:https://blog.csdn.net/github_36326955/article/details/79910448 kerasGPU配置:https://blog.csdn.net/sinat_26917383/article/details/75633754
GPU参考:https://blog.csdn.net/qq_36427732/article/details/79017835htt…
CUDA+CUDNN驱动及软件安装(Ubuntu)
参考链接: Ubuntu16.04下安装cuda和cudnn的三种方法(亲测全部有效) Ubuntu16.04LTS安装Nvidia显卡驱动cuda8.0cudnn
一、安装CUDA
1.下载cuda
2.禁用ubuntu自带的nouveau
终端中运行:$ lsmod | grep nouveau,如…
“Failed to get convolution algorithm. This is probably because cuDNN failed to initialize”错误的解决办法
最近在使用TF2.0。运行程序出现以下错误。
Failed to get convolution algorithm. This is probably because cuDNN failed to initialize一开始怀疑是CUDA和CuDNN配置错误(要求版本匹配)。反复试验后,还是有这个错误。 最后发现可能是GPU内…
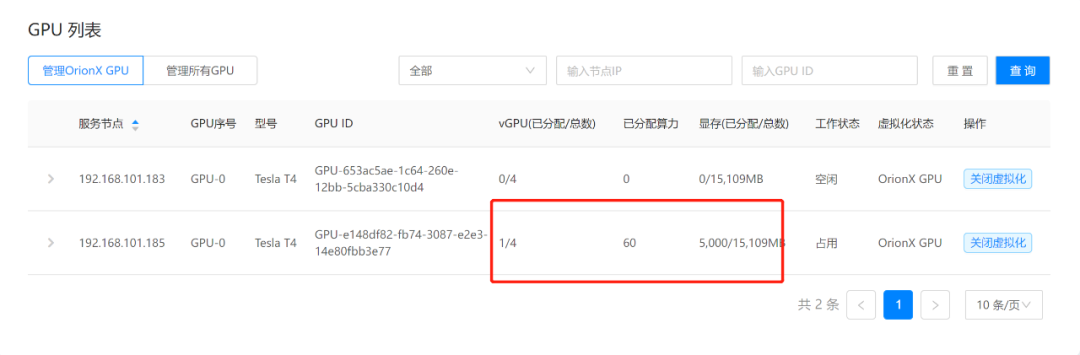
OrionX vGPU研发测试场景下最佳实践之SSH模式
开发机场景概述
目前很多企业在做AI开发的场景时,对GPU资源的管理都是非常简单粗暴的。他们大多都是以开发小组为管理单位、由运维以台为单位分配给开发工程师使用。而在AI开发中涉及开发的场景和测试的场景,很多是将开发测试甚至训练任务都放在一起来使…

【GPU】深入理解GPU硬件架构及运行机制
深入理解GPU硬件架构及运行机制 作者:Tim在路上 曾看到有一篇名为《The evolution of a GPU: from gaming to computing》的文章。
这篇文章非常热烈的讨论了这些年GPU的进步,这引发了我们的一些思考:
为什么我们总说GPU比CPU要强大,既然…
V100 GPU服务器安装CUDNN教程
大家好,我是爱编程的喵喵。双985硕士毕业,现担任全栈工程师一职,热衷于将数据思维应用到工作与生活中。从事机器学习以及相关的前后端开发工作。曾在阿里云、科大讯飞、CCF等比赛获得多次Top名次。现为CSDN博客专家、人工智能领域优质创作者。喜欢通过博客创作的方式对所学的…

cuda12+vs2019环境搭建 发疯实录
点击exe文件后开始安装(注意更改默认安装的位置) 在选项阶段,全选所有的选项
出现的问题,这里显示未安装 进一步地查看原因 可能式对应的版本下载错误 如何寻找到所需要的版本并进行下载? 在上述参考链接中进行搜…

论软件定义GPU对AI数据中心优化的必要性
目录 摘要:
AI数据中心的痛点
解决痛点的方向——GPU池化技术
OrionX GPU池化软件的效率
总结 摘要:
今天AI数据中心为企业提供了深度学习开发、测试和生产所需的软硬件环境。然而,GPU作为高价值硬件,却并没有做到像SDN网络、…
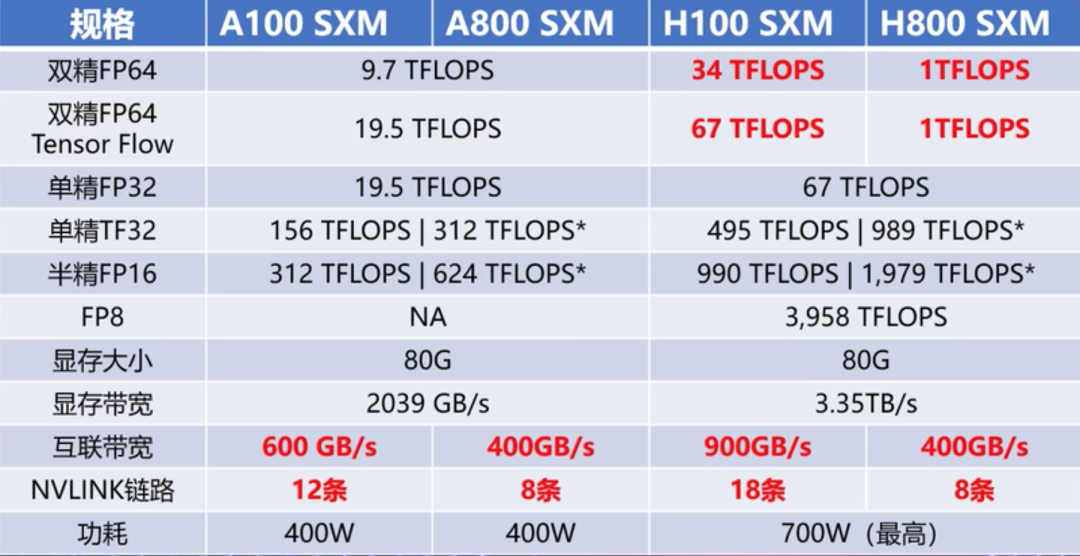
英伟达 V100、A100/800、H100/800 GPU 对比
近期,不论是国外的 ChatGPT,还是国内诸多的大模型,让 AIGC 的市场一片爆火。而在 AIGC 的种种智能表现背后,均来自于堪称天文数字的算力支持。以 ChatGPT 为例,据微软高管透露,为 ChatGPT 提供算力支持的 A…
V100 GPU服务器安装CUDA教程
大家好,我是爱编程的喵喵。双985硕士毕业,现担任全栈工程师一职,热衷于将数据思维应用到工作与生活中。从事机器学习以及相关的前后端开发工作。曾在阿里云、科大讯飞、CCF等比赛获得多次Top名次。现为CSDN博客专家、人工智能领域优质创作者。喜欢通过博客创作的方式对所学的…

深度学习中指定特定的GPU使用
目录 前言1. 问题所示2. 解决方法 前言
老生常谈,同样的问题,主要来源于:RuntimeError: CUDA error: out of memory
当使用完之后,想从其他方式调试,具体可看我这篇文章的:出现 CUDA out of memory 的解决…

突破大模型 | Alluxio助力AI大模型训练-成功案例(一)
更多详细内容可见《Alluxio助力AI大模型训练制胜宝典》
【案例一:知乎】多云缓存在知乎的探索:从UnionStore到Alluxio 作者:胡梦宇-知乎大数据基础架构开发工程师(内容转载自InfoQ) 一、背景
随着云原生技术的飞速发展ÿ…
Windows11搭建GPU版本PyTorch环境详细过程
Anaconda安装
https://www.anaconda.com/
Anaconda: 中文大蟒蛇,是一个开源的Python发行版本,其包含了conda、Python等180多个科学包及其依赖项。从官网下载Setup:点击安装,之后勾选上可以方便在普通命令行cmd和PowerShell中使用…

NVIDIA Edify 为视觉内容提供商解锁 3D 生成 AI 和新图像控件
NVIDIA Edify 为视觉内容提供商解锁 3D 生成 AI 和新图像控件
Shutterstock 3D 一代进入抢先体验阶段; Getty Images 为企业推出定制微调; Adobe 将为 Firefly 和 Creative Cloud 创作者带来 3D 生成人工智能技术; Be.Live、Bria 和 Cuebric…
【Ansys Fluent Web 】全新用户界面支持访问大规模多GPU CFD仿真
基于Web的技术将释放云计算的强大功能,加速CFD仿真,从而减少对硬件资源的依赖。 主要亮点
✔ 使用Ansys Fluent Web用户界面™(UI),用户可通过任何设备与云端运行的仿真进行远程交互 ✔ 该界面通过利用多GPU和云计算功…
GPU检测显卡是否空闲排队程序
GPU检测显卡是否空闲排队程序
本程序特有地加入了检测部分显卡空闲时,可以使用部分显卡直接运行程序,更加实用 测试GPU为3090,不同型号可能略有差别
import os
import sys
import time
from IPython import embed
CUDA_cmd CUDA_VISIBLE_D…

Training Deep Nets with Sublinear Memory Cost
《Training Deep Nets with Sublinear Memory Cost》笔记 摘要
我们提出了一种减少深度神经网络训练时内存消耗的系统性方法。具体来说,我们设计了一个算法,训练一个 nn层网络仅耗费 O(n)" style="position: relative;" tabindex="…

当GPU资源池化遇到量化
目录
01 量化投资的兴起
02 量化交易与量化分析
03 人工智能赋能量化金融
04 量化交易平台
05 GPU资源池化赋能AI量化平台
01 量化投资的兴起
20世纪 60 年代,宽客之父爱德华索普利创立了“科学股票市场系统”,并合伙成立了第一只量化投资…

聊聊GPU通信那些事
目录
引言
一、单机内部GPU的通信
二、多机之间GPU的通信
三、GPU与存储系统的通信
四、总结 引言
AI应用所涉及的技术能力包括语音、图像、视频、NLP、知识图谱等,所有的这些AI技术都需要强大的计算资源来支撑。现在,很多企业内部都拥有一定规模的…
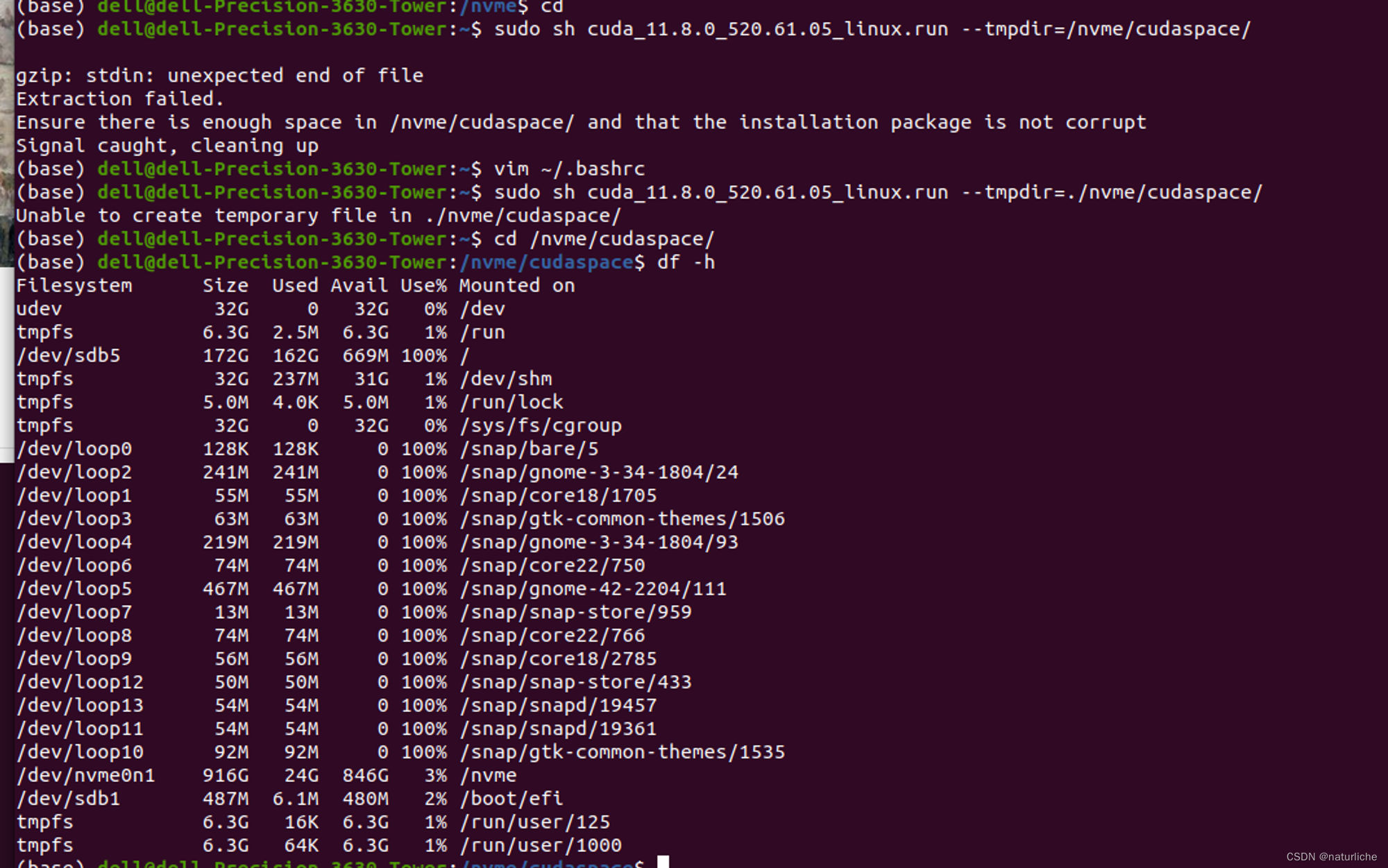
ubuntu 显卡驱动/cuda/cudnn
显卡驱动 https://www.bilibili.com/video/BV1Zc41137tU/?spm_id_from333.999.0.0&vd_sourced75fca5b05d8be06d13cfffd2f4f7ab5
使用recommended的驱动,open和无open的区别在于无open更适合发挥NVIDIA显卡的全部功能和性能,特别是GPU加速计算等任…

【腾讯云】CVM云主机GN7.LARGE20--1/4Tesla T4 显卡驱动【注意事项】
由于项目中需要调用深度学习模型,有gpu的话能够加快运行速度,故购买了腾讯云的GN7.LARGE20实例
查看显卡和显卡驱动:
$ lspci | grep -i nvidia
00:08.0 3D controller: NVIDIA Corporation TU104GL [Tesla T4] (rev a1)
$ lshw -numeric -…
GPU并行计算- 基础知识
逻辑与物理层次的区别: 逻辑层次: 当我们设计CUDA程序时,我们首先需要定义线程的组织结构,包括线程块(blocks)和线程网格(grids)。这种组织方式给予我们逻辑上的控制权,方便我们根据算法的需求进…

Hierarchical Roofline Performance Analysis for Deep Learning Applications
Roofline 模型是劳伦斯伯克利国家实验室在2008年提出的一个性能模型,后续很多工作亦出自该实验室。考虑到分层 Roofline 这一概念已在先前的 Hierarchical Roofline analysis for GPUs: Accelerating performance optimization for the NERSC-9 Perlmutter system 和…
Linux篇之在Centos环境下搭建Nvidia显卡驱动
一、前提条件 1、首先确认内核版本和发行版本,再确认显卡型号
uname -a
// Linux localhost.localdomain 4.18.0-408.el8.x86_64 #1 SMP Mon Jul 18 17:42:52 UTC 2022 x86_64 x86_64 x86_64 GNU/Linux1.2
cat /etc/redhat-release
// CentOS Stream release 81.3…
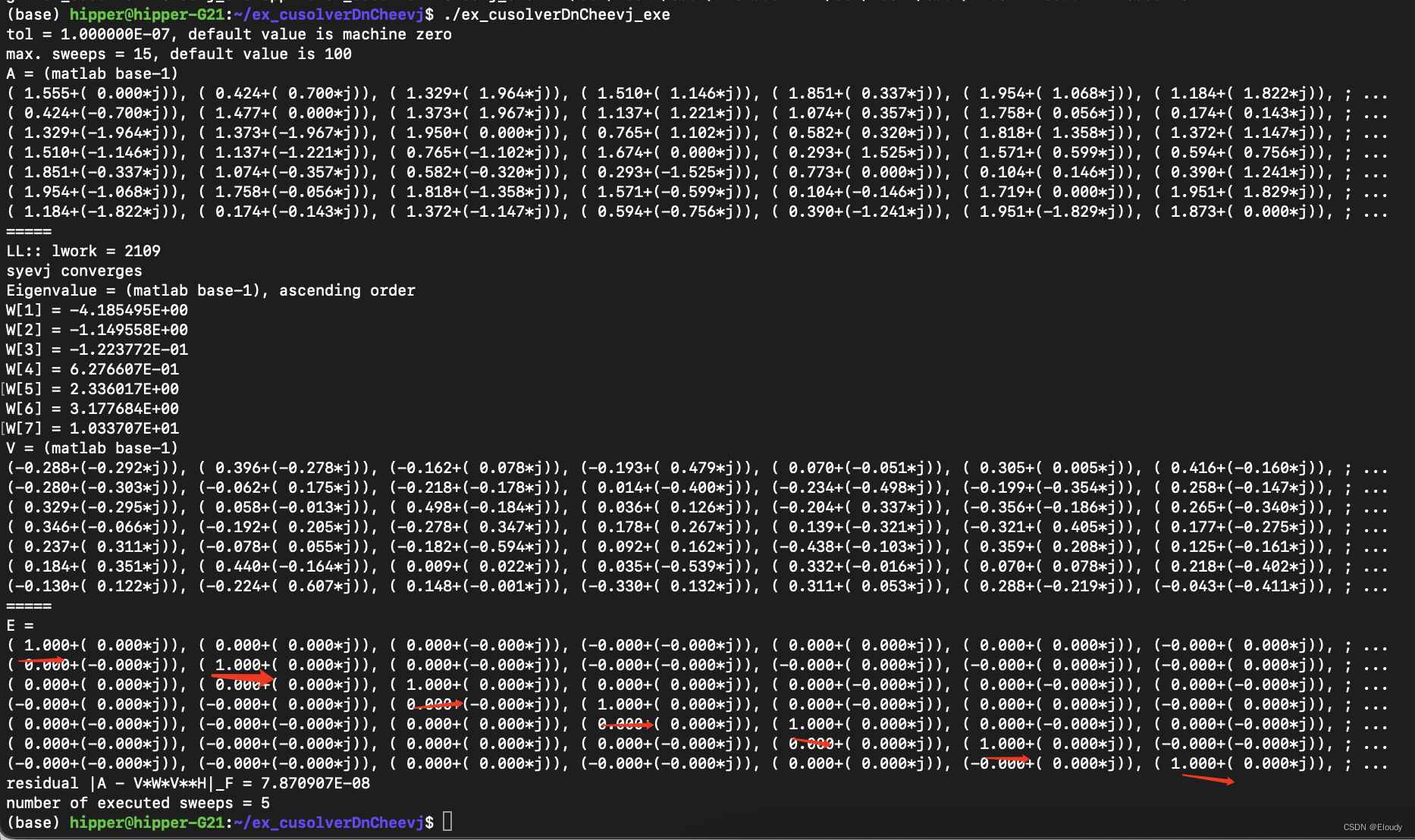
计算 Hermitian 矩阵的特征值和特征向量 cusolver 示例 DnCheevj
1,原理
计算Hermitian 矩阵的特征值,使用Jacobi 旋转法,每次调整两个对称元素为0,通过迭代,使得非对角线上的值总体越来越趋近于0.
示例扩展了 nv 的 cusolverDsyevj 的示例
由于特征向量是正交的,故V*V…
英伟达发布 RTX30 系列 ,纪念的是 21 年前的哪张神卡?
By 超神经内容概要:英伟达在今天凌晨发布了 RTX 30 系列新品,在此之前的宣传内容中多次提及 21 年前的重大发布,本文将回顾 21 年前的 1999 年前后,NVIDIA 所经历的重要时刻。关键词:英伟达 GPU 商业分析美西时间 9 月…
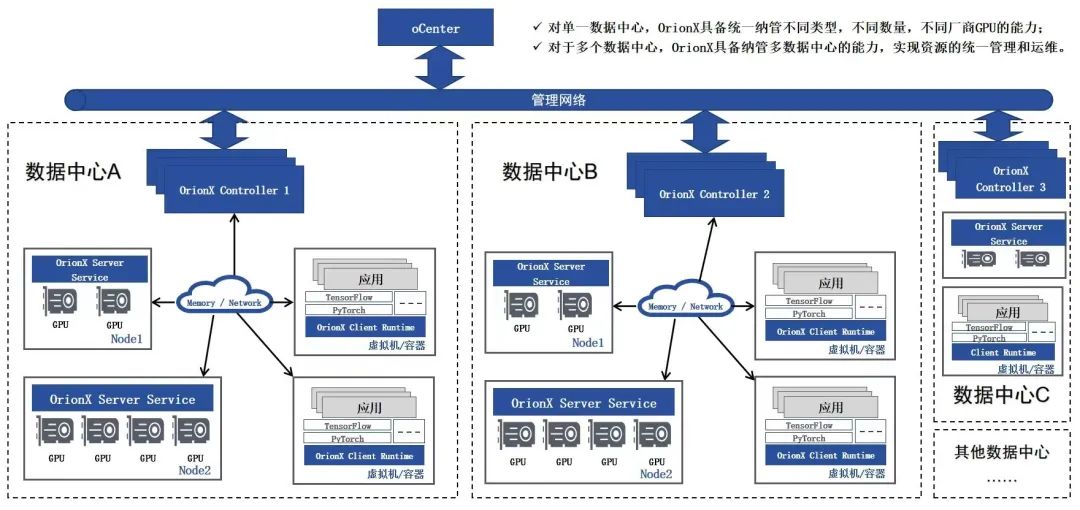
盘活存量GPU资源 破局高校算力不足窘境
“凭啥做大模型的优先分配算力?人家1个人4块A800,我们10个人用2块3090!这日子没法过了!”听着团队成员们的吐槽,某国内顶尖高校非大模型团队带队的博士老W也颇为无奈:“我们虽然不是做大模型的,…
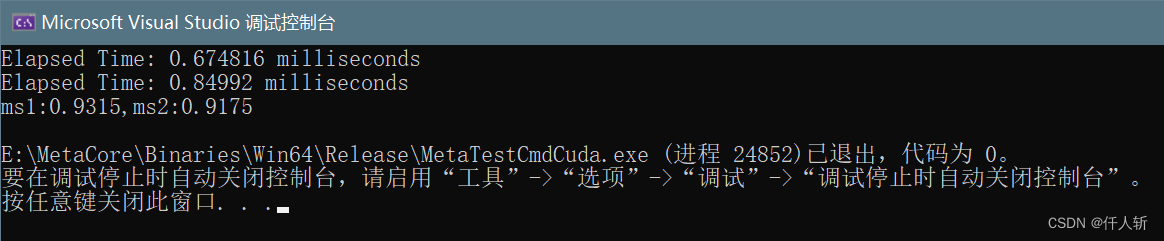
GPU CUDA 使用shared memory 运行速度不升反降原因与解决方案
写了两张图像相加,以及图像滤波的的几个算子,分别采用shared memory 进行优化。
#include <stdio.h>
#include <cuda_runtime.h>#include "helper_cuda.h"
#include "helper_timer.h"#define BLOCKX 32
#define BLOCKY…
tf.ConfigProto() 和tensorflow的GPU配置
# 使用0, 2, 3三块GPU
os.environ[CUDA_VISIBLE_DEVICES] 0, 2, 3#设置每个GPU应该拿出多少容量给进程使用,0.6表示60%
gpu_optionstf.GPUOptions(per_process_gpu_memory_fraction0.6)configtf.ConfigProto(gpu_optionsgpu_options,log_device_placeme…

NVIDIA Jetson TX1(3)
2.0 电源和系统管理
Jetson TX1模块设计思想是易于系统集成,它单电源供电(VDD_IN),还有一个可选的备份电池输入VDD_RTC,这个电源用来维持系统RTC。
Jetsin TX1模块要求电源以一个已知的顺序进行开关,顺序…
AI时代显卡如何选择,B100、H200、L40S、A100、H100、V100 含架构技术和性能对比
AI时代显卡如何选择,B100、H200、L40S、A100、H100、V100 含架构技术和性能对比。
英伟达系列显卡大解析B100、H200、L40S、A100、A800、H100、H800、V100如何选择,含架构技术和性能对比带你解决疑惑。
近期,AIGC领域呈现出一片繁荣景象&a…
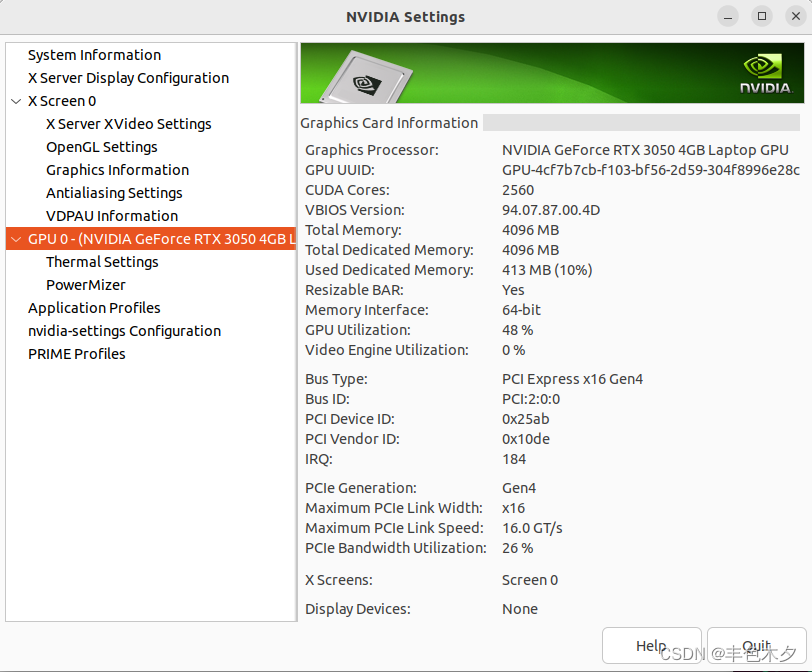
ubuntu下如何查看显卡及显卡驱动
ubuntu下如何查看显卡及显卡驱动
使用nvidia-smi 工具查看
查看显卡型号nvida-smi -L
$ nvidia-smi -L
GPU 0: NVIDIA GeForce RTX 3050 4GB Laptop GPU (UUID: GPU-4cf7b7cb-f103-bf56-2d59-304f8996e28c)当然直接使用nvida-smi 命令可以查看更多信息
$ nvidia-smi
Mon Fe…
Tensorflow学习笔记十五——加速计算
1.Tensorflow单机实现
import tensorflow as tfatf.Variable(tf.constant([1.0,shape[1]),name"a")
btf.Variable(tf.constant([3.0,shape[1]),name"b")
resultab
init_optf.global_variables_initializer()with tf.Session(configtf.COnfigProto(log_dev…
pytorch 使用gpu
#在这里介绍一下如何在torch中导入GUP 1、先检测有无设备 device torch.device(“cuda:0” if torch.cuda.is_available() else “cpu”)
if torch.cuda.device_count() > 1: print(“Let’s use”, torch.cuda.device_count(), “GPUs”)
2、再将相应的数据变成tensor的…
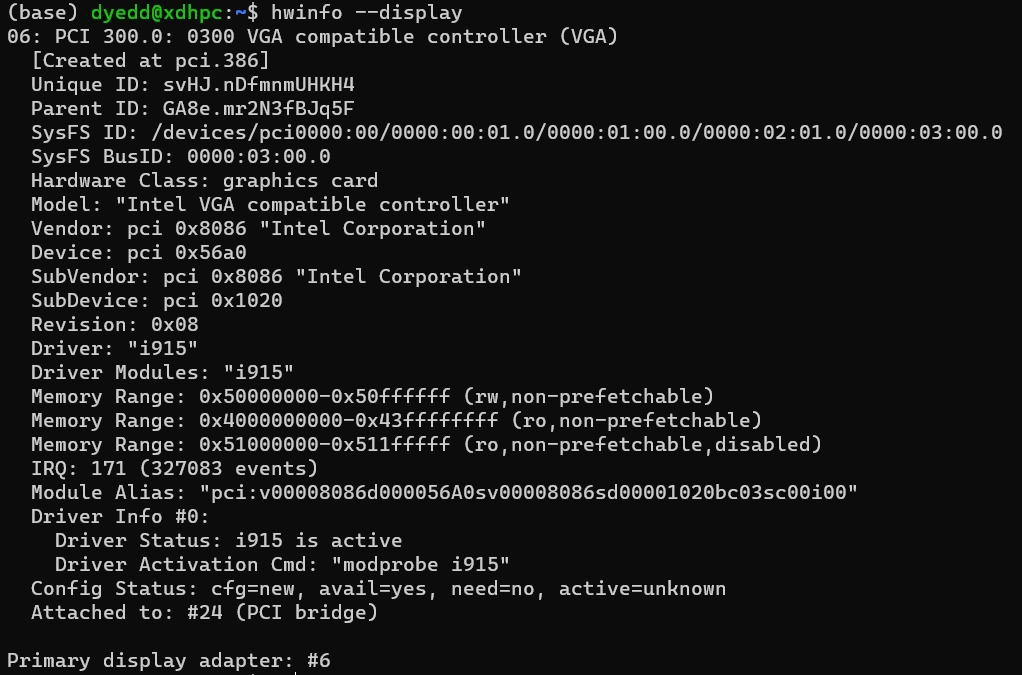
英特尔生态的深度学习科研环境配置-A770为例
之前发过在Intel A770 GPU安装oneAPI的教程,但那个方法是用于WSL上。总所周知,在WSL使用显卡会有性能损失的。而当初买这台机器的时候我不在场,所以我这几天刚好有空把机器给重装成Ubuntu了。本篇不限于安装oneAPI,因为在英特尔的…
【GPU驱动开发】- GPU架构流程
前言
不必害怕未知,无需恐惧犯错,做一个Creator!
一、总述
GPU(Graphics Processing Unit,图形处理单元)是一种专门用于处理图形和并行计算的处理器。GPU系统架构通常包括硬件和软件层面的组件。 总体流…
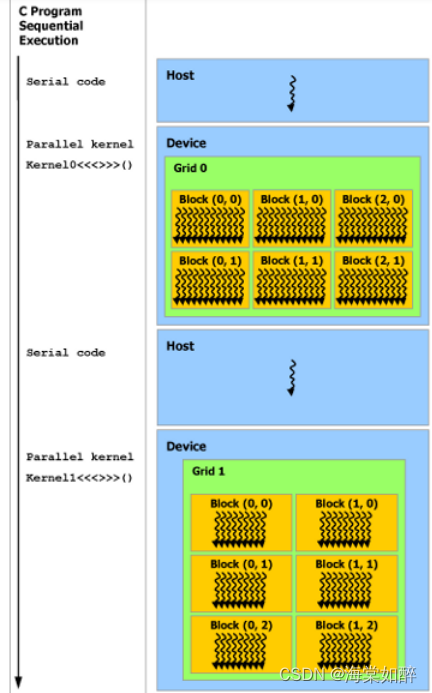
GPU-CPU-ARM-X86-RISC-CUDA
CPU更适合处理复杂逻辑运算和单线程任务,而GPU则更适合处理大规模并行计算任务。
CPU(中央处理器)通常具有较少的核心数量(一般在2到16个之间),但每个核心的性能较强,擅长执行复杂的运算和逻辑…
CUDA编程之GPU图像数据结构的设计
第1章 GPU图像数据结构
参考OpenCV中Mat和GpuMat的设计,对当前Image类设计了GPU版本,即GPUImage。
1.1. GPU图像头
设计图像头。
struct GPUImageHeader
{int32_t nWidth = 0; //宽度int32_t nHeight = 0; //高度int16_t nChannel = 0; //通道数int32_t nRefCount = …
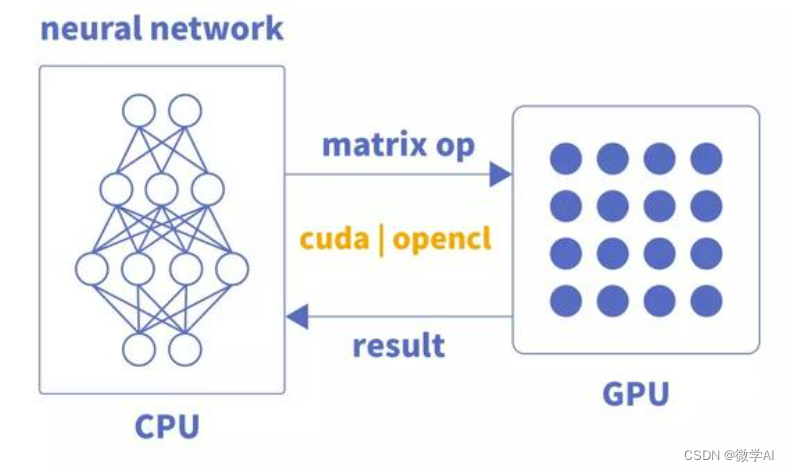
人工智能基础部分16-神经网络与GPU加速训练的原理与应用
大家好,我是微学AI,今天给大家介绍一下人工智能基础部分16-神经网络与GPU加速训练的原理与应用,在深度学习领域,神经网络已经成为了一种流行的、表现优秀的技术。然而,随着神经网络的规模越来越大,训练神经…
使用GPU硬件加速FFmpeg视频转码
最近看了些视频处理相关的文章,这里有一篇是讲如何使用Nvidia显卡为视频的编解码进行加速的,
为了方便查阅就转载了: 本文内容包括:
在Linux环境下安装FFmpeg通过命令行实现视频格式识别和转码有Nvidia显卡的情况下,…
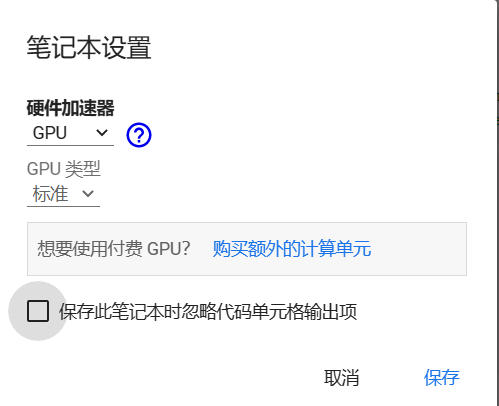
如何在Colab中使用gpu资源(附使用MMdet推理示例)
如何在Colab中“白嫖”gpu资源(附使用MMdet推理示例)
Google Colab简介
当今,深度学习已经成为许多人感兴趣的话题,Google Colab(全称为Google Colaboratory)是Google推出的一个强大的云端 notebook&…

Tensorflow在训练模型的时候如何指定GPU进行训练
Tensorflow指定GPU进行训练模型
实验室共用一个深度学习服务器,两块GPU,在用tensorflow训练深度学习模型的时候,假设我们在训练之前没有指定GPU来进行训练,则默认的是选用第0块GPU来训练我们的模型,而且其它几块GPU的也会显示被占…

【GPU驱动开发】-mesa简介
前言
不必害怕未知,无需恐惧犯错,做一个Creator!
一、mesa介绍
Mesa是OpenGL、Vulkan和其他图形API规范的开源实现。主要由Intel和AMD为其各自的硬件开发和资助。 AMD 在已弃用的AMD Catalyst上推广其 Mesa 驱动程序 Radeon 和 RadeonSI &…

用deviceQuery查看GPU状态
用xshell连接服务器 执行deviceQuery命令
cuda的deviceQuery命令位置:/usr/local/cuda-10.2/samples/1_Utilities/deviceQuery 将deviceQuery文件夹复制到目标位置
cp /usr/local/cuda-10.2/samples/1_Utilities/deviceQuery /jnhan用make编译
make此时ÿ…

极智芯 | 存算一体 弯道超车的希望
欢迎关注我的公众号 [极智视界],获取我的更多经验分享
大家好,我是极智视界,本文分享一下 存算一体 弯道超车的希望。 邀您加入我的知识星球「极智视界」,星球内有超多好玩的项目实战源码和资源下载,链接:…
CUDA Sample中的reduce实现
我们知道,GPU擅长做并行计算,像element-wise操作。GEMM, Conv这种不仅结果张量中元素的计算相互不依赖,而且输入数据还会被反复利用的更能体现GPU的优势。但AI模型计算或者HPC中还有一类操作由于元素间有数据依赖,会给并行化带来挑…
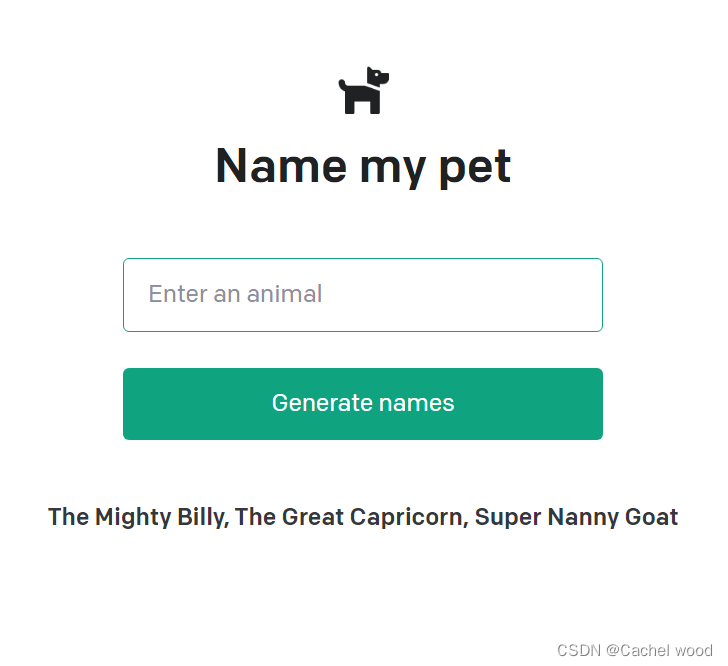
python openai宠物名字生成器
文章目录 OpenAICompletion宠物名字生成器提示词工程 prompt enginering 构建应用程序结果展示 OpenAI
OpenAI 已经训练了非常擅长理解和生成文本的领先的语言模型。我们的 API 提供对这些模型的访问,可用于处理几乎任何涉及”语言处理“的任务。
Completion
补全…
智慧零售技术探秘:关键技术与开源资源,助力智能化零售革新
智慧零售是一种基于先进技术的零售业态,通过整合物联网、大数据分析、人工智能等技术,实现零售过程的智能化管理并提升消费者体验。
实现智慧零售的关键技术包括商品的自动识别与分类、商品的自动结算等等。
为了实现商品的自动识别与分类,…
Ubuntu 14.04 64bit + CUDA7.0卸载+ CUDA 6.5 安装配置
实验室要做的项目需要用到某个项目的开源,只支持到CUDA6.5,而我本机上的版本是CUDA7.0,没有办法,先卸载,再安装;步骤如下:
一,卸载CUDA 7.0
在目录:
# /usr/local/cud…

GPU 与 CPU?什么是 GPU 计算?|NVIDIA
转载自 http://www.nvidia.cn/object/what-is-gpu-computing-cn.html 什么是 GPU 加速计算?GPU 加速计算是指同时利用图形处理器 (GPU) 和 CPU,加快科学、分析、工程、消费和企业应用程序的运行速度。GPU 加速器于 2007 年由 NVIDIA 率先推出,…
Metal入门学习:绘制渲染三角形
一、编程指南PDF下载链接(中英文档) 1、Metal编程指南PDF链接 https://github.com/dennie-lee/ios_tech_record/raw/main/Metal学习PDF/Metal 编程指南.pdf 2、Metal着色语言(Metal Shader Language:简称MSL)编程指南PDF链接 https://github.com/dennie-lee/ios_te…
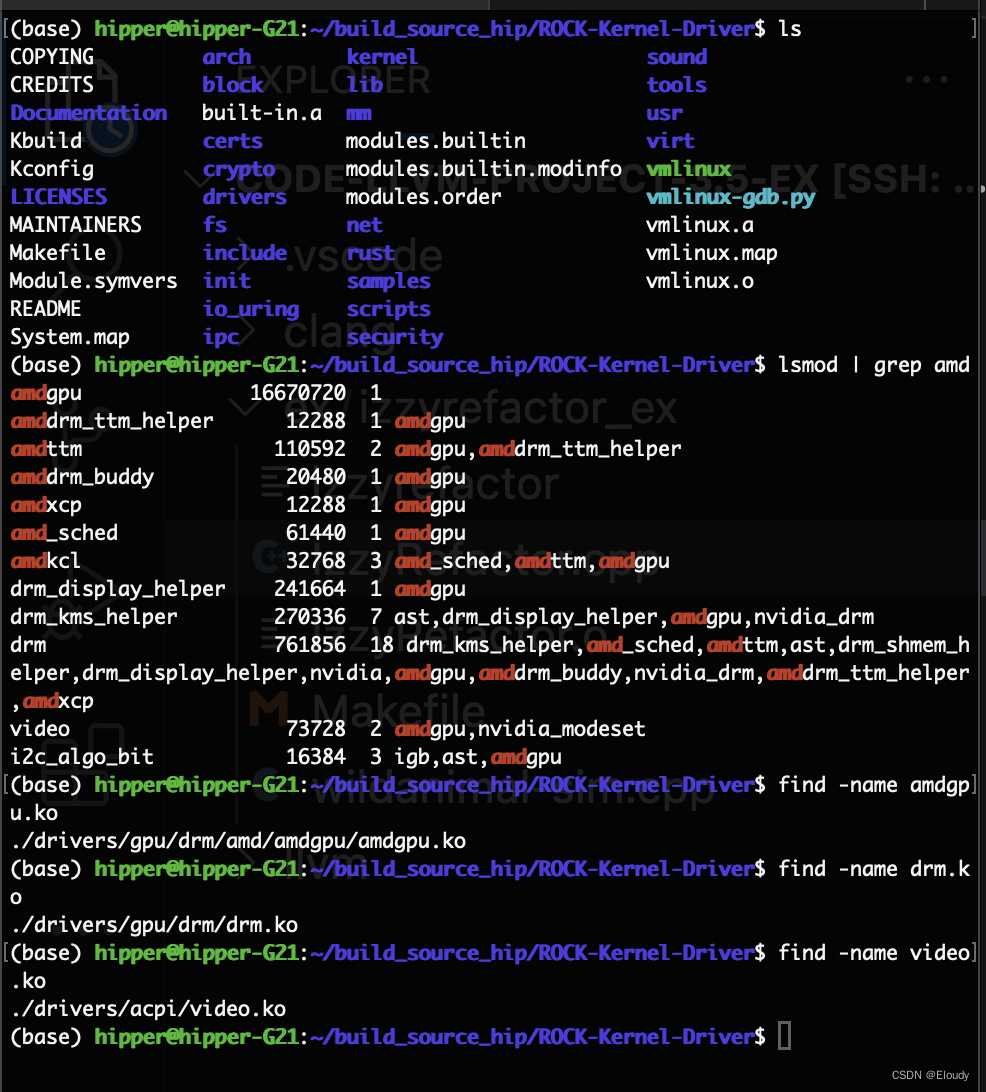
编译 amd gpu 核心态驱动 rocm kmd linux kernel
AMD 开源了专门的 ROCm 的kmd Linux Kernel,
1,下载源代码
git clone --recursive https://github.com/ROCm/ROCK-Kernel-Driver.gitcd ROCK-Kernel-Driver/git checkout rocm-6.0.22,配置kernel
cp -v /boot/config-$(uname -r) .config make menuconfig
Graph…
NVIDIA_Tesla_V100_PCIe_32GB加速卡详细参数
记录了NVIDIA_Tesla_V100_PCIe_32GB加速卡的详细参数 参考链接: https://www.xincanshu.com/gpu/NVIDIA_Tesla_V100_PCIe_32_GB/canshu.html
主要参数
参数值描述核心频率1230 MHz核心 一秒内能够进行多少处理周期Turbo频率1380 MHz突发加速频率,类似于CPU睿频流处…
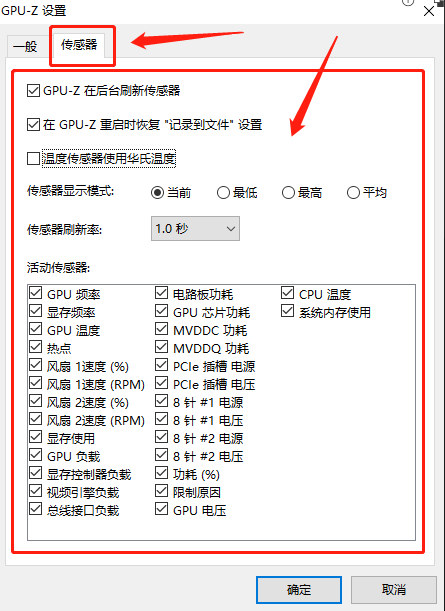
显卡检测工具:GPU-Z
今天小编为大家测试了一款轻量级的GPU显卡的测试工具,可以查看GPU的详细信息,以供各位同学们学习。 一、简单介绍
GPU-Z是一款方便实用的软件工具,专门为用户提供视频卡和GPU的详尽信息。它具有轻巧的特点,不需要安装即可使用&am…
ModaHub魔搭社区:向量数据库的工作原理
目录
1. 为什么需要向量数据库
1)CPU 工作原理
2)GPU 工作原理
3)二者的差异
4)总结
5)大模型的工作原理
学习
推理 1. 为什么需要向量数据库
向量数据库这一概念随着黄仁勋的演讲火爆了之后,不少…
编译amd 的 amdgpu 编译器
1,下载源码
git clone --recursive https://github.com/ROCm/llvm-project.git 2, 配置cmake
cmake -G "Unix Makefiles" ../llvm \
-DLLVM_ENABLE_PROJECTS"clang;clang-tools-extra;compiler-rt" \
-DLLVM_BUILD_EXAMPLESON …
【GPU驱动开发】-GPU架构简介
前言
不必害怕未知,无需恐惧犯错,做一个Creator!
GPU(Graphics Processing Unit,图形处理单元)是一种专门用于处理图形和并行计算的处理器。GPU系统架构通常包括硬件和软件层面的组件。
一、总体流程
应…

DDP学习/PyTorch多GPU训练/查看模型在哪个GPU上
参考:
pytorch如何查看tensor和model在哪个GPU上 https://blog.csdn.net/weixin_37889356/article/details/121792888Part 3: Multi-GPU training with DDP (code walkthrough) [pytorch官方教程,有股咖喱味的Inglish, 推荐] https://www.youtube.com/w…

CUDA中的动态并行
CUDA的动态并行 文章目录CUDA的动态并行1. 介绍1.1. 简述警告:与父块的子内核显式同步(即在设备代码中使用 cudaDeviceSynchronize())在 CUDA 11.6 中已弃用,并计划在未来的 CUDA 版本中删除。1.2. 术语2. 执行环境和内存模型2.1.…
xgboost配置GPU
说明:博主的显卡为3090,驱动为470.94,CUDA版本为11.4,cmake 3.3.2,gcc 7.3.1 以上版本配置xgboost(2.0.0)GPU可以直接调用 直接安装即可 pip install xgboost==2.0.0
1、测试GPU代码
如果测试不通过,考虑2、3
import xgboost as xgb
from sklearn.datasets import l…
flash attention论文及源码学习
论文
attention计算公式如下
传统实现需要将S和P都存到HBM,需要占用 O ( N 2 ) O(N^{2}) O(N2)内存,计算流程为
因此前向HBM访存为 O ( N d N 2 ) O(Nd N^2) O(NdN2),通常N远大于d,GPT2中N1024,d64。HBM带宽…

CUDA相关知识科普
显卡
显卡(Video card,Graphics card)全称显示接口卡,又称显示适配器,是计算机最基本配置、最重要的配件之一。就像电脑联网需要网卡,主机里的数据要显示在屏幕上就需要显卡。因此,显卡是电脑进…
【ChatGLM3】第三代大语言模型多GPU部署指南
关于ChatGLM3
ChatGLM3是智谱AI与清华大学KEG实验室联合发布的新一代对话预训练模型。在第二代ChatGLM的基础之上,
更强大的基础模型: ChatGLM3-6B 的基础模型 ChatGLM3-6B-Base 采用了更多样的训练数据、更充分的训练步数和更合理的训练策略。在语义、…
c++矩阵计算性能对比:Eigen和GPU
生成随机矩阵 生成随机矩阵有多种方式,直接了当的方式是使用显式循环的方式为矩阵的每个元素赋随机值。
#include <iostream>
#include <random>using namespace std;// 生成随机数
double GenerateRandomRealValue()
{std::random_device rd;std::def…

高性能计算工程师工资一般多少?
由于近两年深度学习的迅速崛起,超算互联网的普及以及AIGC的大规模应用,各行各业对高性能计算工程师的需求大涨,因此高性能计算工程师的工资也在逐年上涨中,并频频爆发抢人大战。 甚至年薪百万依然难以招到合适的人才。 有很多大厂…
NVIDIA NCCL 源码学习(十)- 多机间ncclSend和ncclRecv的过程
先回忆一下单机的执行流程,用户执行ncclSend之后通过ncclEnqueueCheck将sendbuff,sendbytes,peer等信息保存到了comm->p2plist中;然后执行ncclGroupEnd,如果发现channel没有建立到peer的链接则先建链,然…

跨平台Caffe及I/O模型与并行方案(四)
4. Caffe多GPU并行方案
4.1 多GPU并行概述 得益于训练数据的爆炸性增长和计算性能的巨大提升,深度学习算法能够学习数据的分布和分层的特征表示,从而更好地解决模式分析和分类等任务。面对巨大的数据规模和复杂的深度学习模型,目前主流的单G…
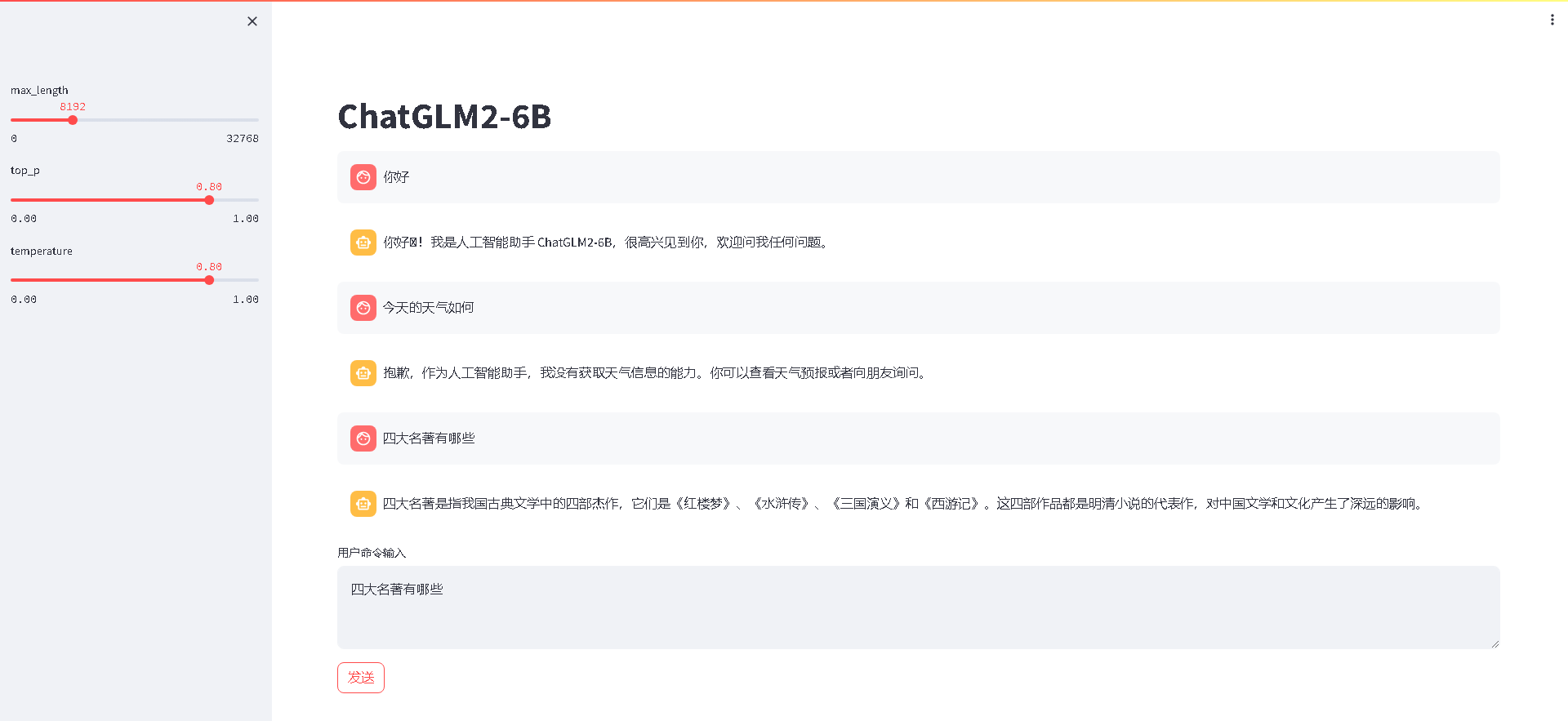
【ChatGLM2-6B】从0到1部署GPU版本
准备机器资源
显卡: 包含NVIDIA显卡的机器,如果是阿里云服务器可以选择ecs.gn6i-c4g1.xlarge规格硬盘: 大约50G左右操作系统: CentOS 7.9 64位CPU内存: 4C16G
更新操作系统
sudo yum update -y
sudo yum upgrade -y下载并安装anaconda
在命令行中,输…
Android SurfaceFlinger导读(01) surfaceFlinger谁写的?他还干了什么?
该系列文章总纲链接:Android GUI系统之SurfaceFlinger 系列文章目录 1 surfaceFlinger作者简介
surfaceFlinger是一个名为Mathias Agopian的工程师编写的。作者Mathias Agopian有着BE和PalmSource的工作经历,于2006年加入了Android团队。他是一个晚睡晚…
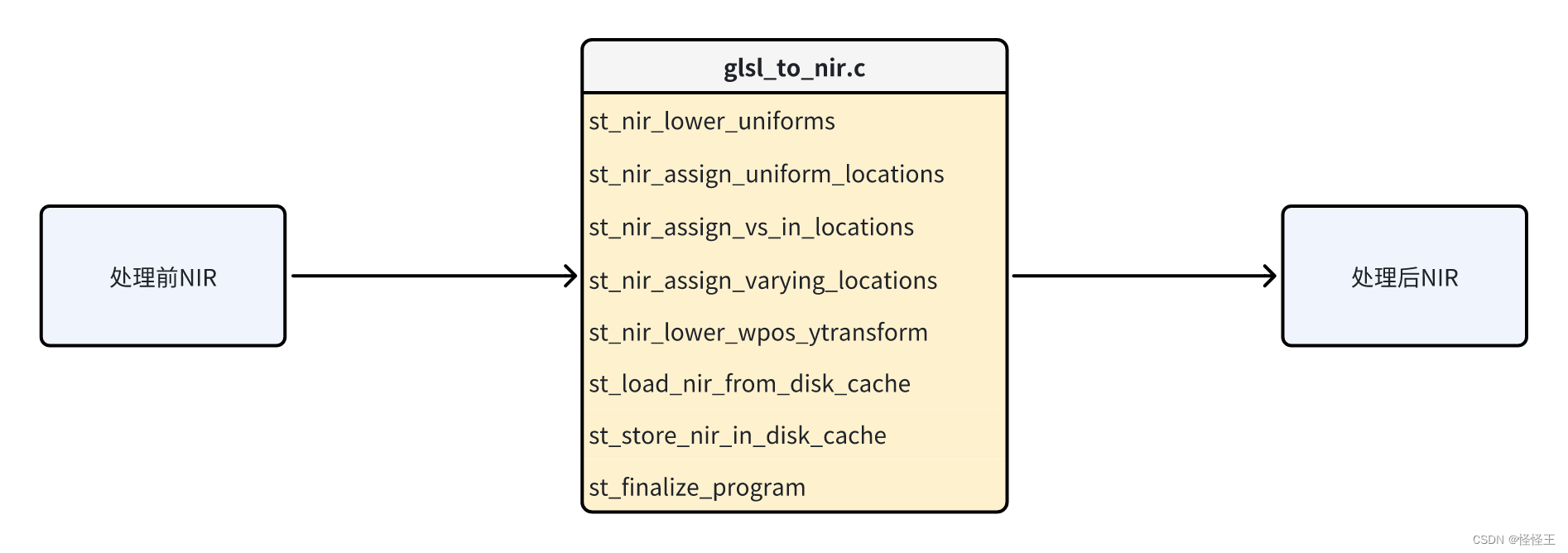
【GPU驱动开发】- mesa编译与链接过程详细分析
前言
不必害怕未知,无需恐惧犯错,做一个Creator!
一、总体框架图
暂时无法在飞书文档外展示此内容
二、Mesa API 处理 OpenGL 函数调用
Mesa API 负责实现 OpenGL 和其他图形 API 的函数接口。Mesa API 表是一个重要的数据结构…

英伟达文本生成3D模型论文:Magic3D: High-Resolution Text-to-3D Content Creation解读
一、摘要 摘要:DreamFusion 最近展示了使用预训练的文本到图像扩散模型来优化神经辐射场 (NeRF) 的实用性,实现了显着的文本到 3D 合成结果。然而,该方法有两个固有的局限性:(a)NeRF 的优化极慢和…